
Auf den Trendlisten! Das große Modell von Meituan wird durch „Schnelligkeit“ populär

Entwickler im In- und Ausland: Aus eigener Erfahrung – das neue Open-Source-Modell von Meituan ist extrem schnell!
Wenn KI wirklich so allgegenwärtig wird wie Wasser und Strom, ist die Leistungsfähigkeit eines Modells nicht mehr das einzige, was alle interessiert.
Von Claude 3.7 Sonnet und Gemini 2.5 Flash zu Beginn des Jahres bis hin zu den aktuellen GPT-5 und DeepSeek V3.1 – alle führenden Modellanbieter denken darüber nach: Wie kann KI bei gleichbleibender Genauigkeit mit möglichst wenig Rechenleistung jedes Problem lösen und gleichzeitig in kürzester Zeit antworten? Anders gesagt: Wie kann man vermeiden, sowohl Tokens als auch Zeit zu verschwenden?
Für Unternehmen und Entwickler, die Anwendungen auf Modellen aufbauen, ist dieser Wandel von „nur das stärkste Modell bauen“ hin zu „praktischere und schnellere Modelle entwickeln“ eine gute Nachricht. Und noch erfreulicher ist, dass immer mehr Open-Source-Modelle in diesem Bereich erscheinen.
Vor einigen Tagen haben wir auf HuggingFace ein neues Modell entdeckt – LongCat-Flash-Chat.

Dieses Modell stammt aus der LongCat-Flash-Serie von Meituan und kann direkt auf der offiziellen Website genutzt werden.
Es weiß von Natur aus, dass „nicht alle Tokens gleich sind“ und weist daher wichtigen Tokens dynamisch Rechenressourcen zu. So kann es mit der Aktivierung von nur wenigen Parametern eine Leistung erzielen, die mit den derzeit führenden Open-Source-Modellen mithalten kann.

Nach der Open-Source-Veröffentlichung von LongCat-Flash wurde es zu einem Trendthema.
Auch die Geschwindigkeit dieses Modells hat einen bleibenden Eindruck hinterlassen – auf einer H800-Grafikkarte erreicht es eine Inference-Geschwindigkeit von über 100 Tokens pro Sekunde. Entwickler im In- und Ausland haben dies bestätigt – einige erreichten 95 Tokens/s, andere erhielten in kürzester Zeit Antworten, die mit Claude vergleichbar sind.
Bildquelle: Zhihu-Nutzer @小小将.
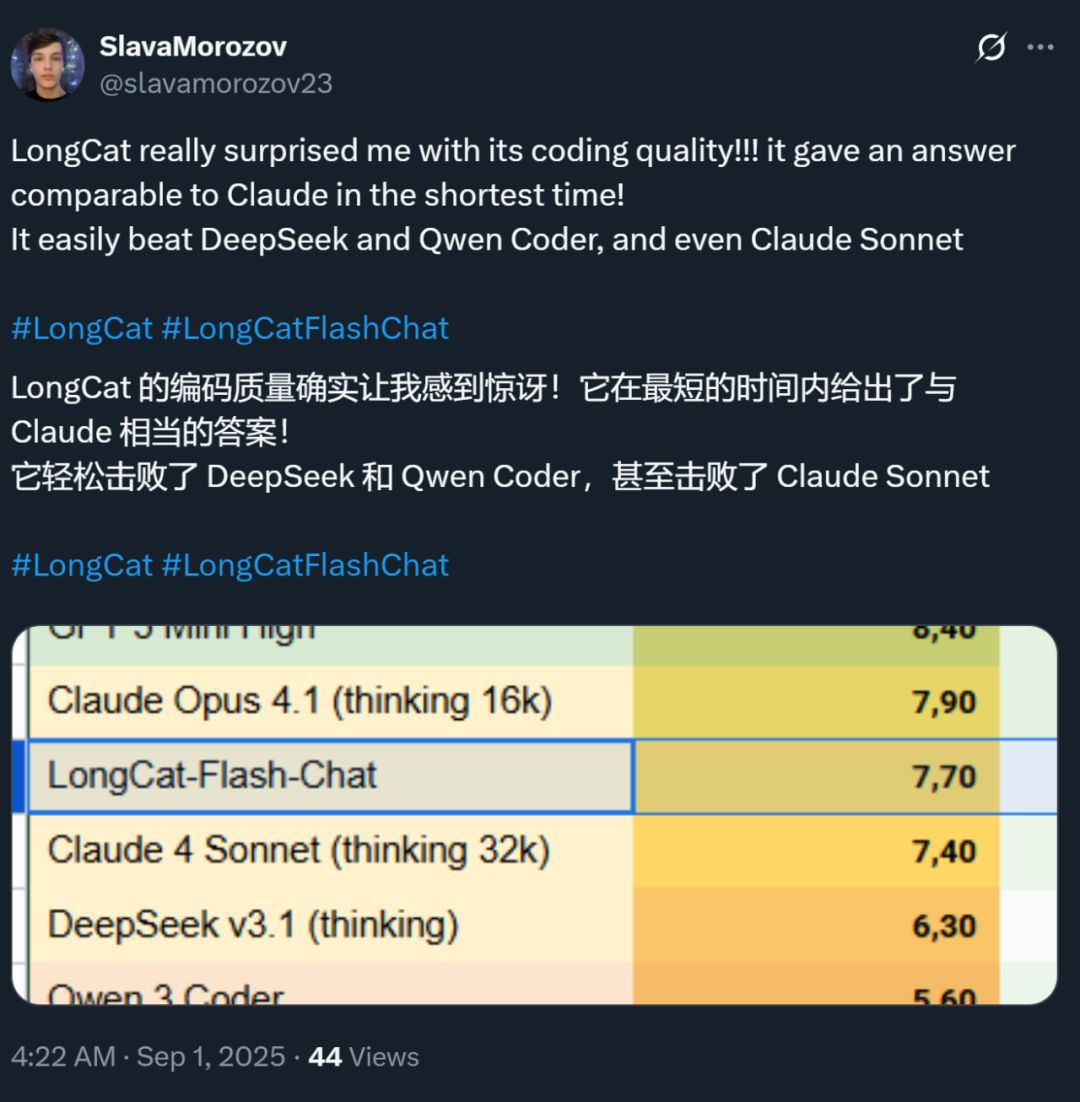
Bildquelle: X-Nutzer @SlavaMorozov.
Gleichzeitig mit dem Open-Sourcing des Modells hat Meituan auch den technischen Bericht zu LongCat-Flash veröffentlicht, in dem viele technische Details zu finden sind.

Technischer Bericht: LongCat-Flash Technical Report
In diesem Artikel stellen wir die Details vor.
Wie sparen große Modelle Rechenleistung?
Ein Blick auf die Architekturinnovationen und Trainingsmethoden von LongCat-Flash
LongCat-Flash ist ein Mixture-of-Experts-Modell mit insgesamt 560 Milliarden Parametern, von denen je nach Kontext 18.6 bis 31.3 Milliarden (im Schnitt 27 Milliarden) Parameter aktiviert werden.
Für das Training dieses Modells wurden mehr als 20 Billionen Tokens verwendet, aber die Trainingszeit betrug weniger als 30 Tage. Während dieser Zeit erreichte das System eine Verfügbarkeit von 98,48%, sodass kaum manuelles Eingreifen zur Fehlerbehebung nötig war – das gesamte Training wurde also praktisch „ohne menschliches Zutun“ automatisch abgeschlossen.
Beeindruckend ist auch, dass das so trainierte Modell bei der tatsächlichen Bereitstellung ebenso herausragend abschneidet.
Wie unten gezeigt, erreicht LongCat-Flash als nicht-denkendes Modell eine vergleichbare Leistung mit SOTA nicht-denkenden Modellen wie DeepSeek-V3.1 und Kimi-K2, benötigt dabei aber weniger Parameter und ist schneller in der Inferenz. Das macht es in Bereichen wie allgemeine Aufgaben, Programmierung und Agent-Tool-Nutzung sehr wettbewerbsfähig und praktisch.
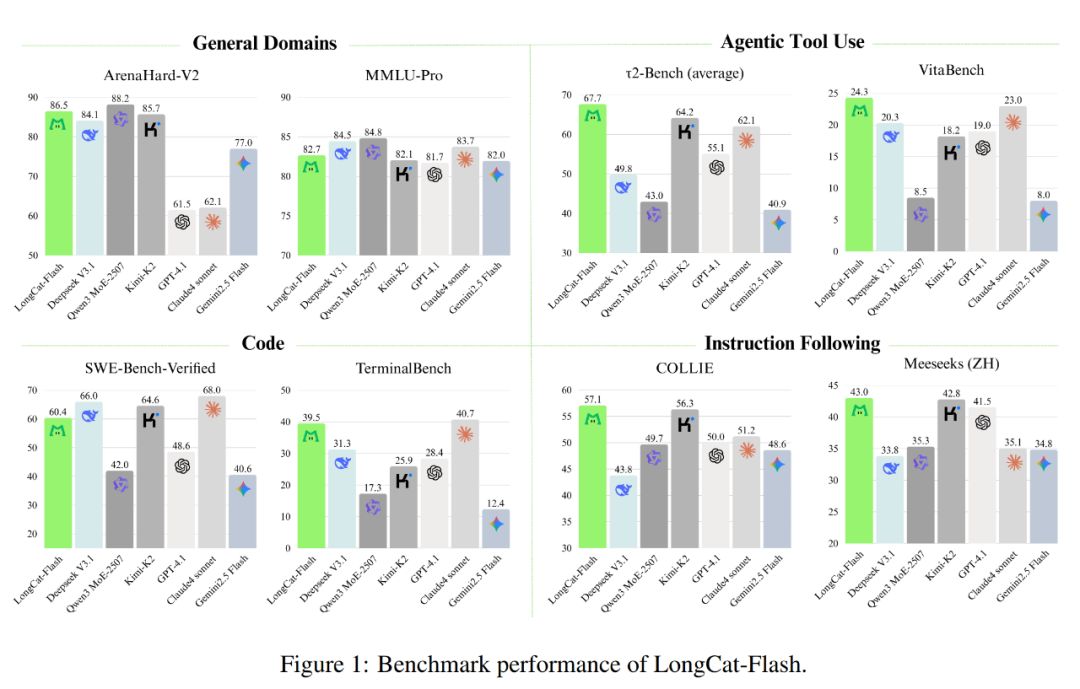
Auch die Kosten sind bemerkenswert: Nur 0,7 US-Dollar pro Million ausgegebener Tokens. Im Vergleich zu Modellen ähnlicher Größe auf dem Markt ist das sehr günstig.
Technisch gesehen zielt LongCat-Flash auf zwei Hauptziele von Sprachmodellen ab: Recheneffizienz und Agentenfähigkeiten. Es kombiniert Architekturinnovationen mit mehrstufigen Trainingsmethoden, um ein skalierbares und intelligentes Modellsystem zu schaffen.
In Bezug auf die Modellarchitektur verwendet LongCat-Flash eine neuartige MoE-Architektur (Abbildung 2) mit zwei Highlights:
Zero-computation Experts;
Shortcut-connected MoE (ScMoE).
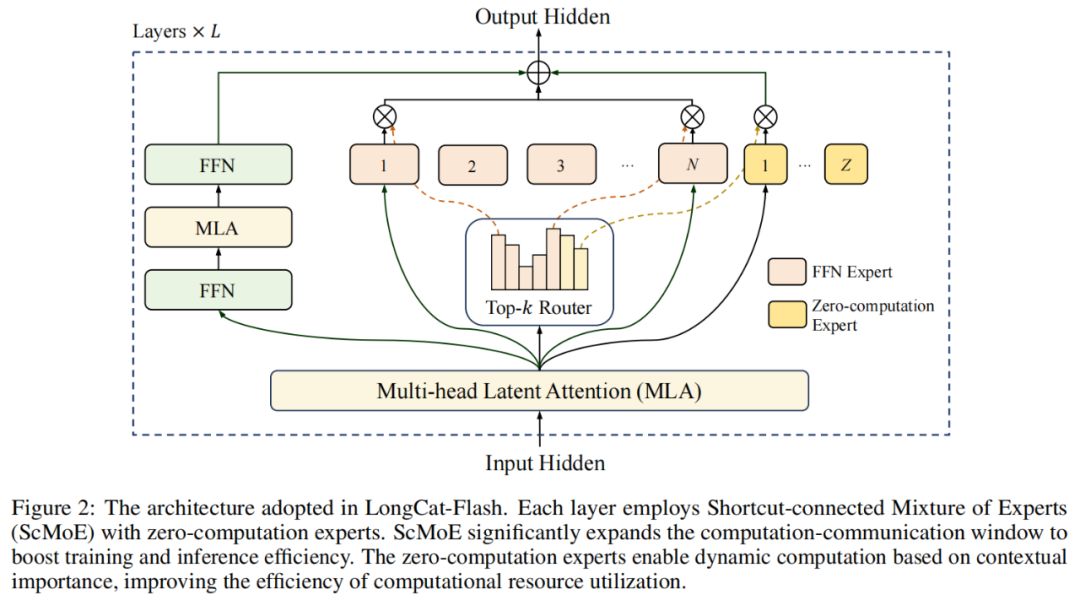
Zero-computation Experts
Der Kern dieser Idee ist, dass nicht alle Tokens „gleich“ sind.
Man kann es so verstehen: In einem Satz sind manche Wörter sehr leicht vorherzusagen, wie „der“, „ist“, die kaum Rechenaufwand benötigen, während andere wie Eigennamen viel Rechenleistung erfordern, um sie korrekt vorherzusagen.
In bisherigen Studien wurde meist folgender Ansatz verwendet: Egal, ob ein Token einfach oder komplex ist, es werden immer eine feste Anzahl (K) Experten aktiviert, was zu enormer Rechenverschwendung führt. Für einfache Tokens ist das unnötig, für komplexe Tokens fehlt es womöglich an ausreichender Rechenzuteilung.
Davon inspiriert, schlägt LongCat-Flash einen Mechanismus zur dynamischen Zuteilung von Rechenressourcen vor: Durch Zero-computation Experts werden für jedes Token unterschiedlich viele FFN (Feed-Forward Network) Experten aktiviert, sodass die Rechenlast je nach Kontextbedeutung sinnvoll verteilt wird.
Konkret erweitert LongCat-Flash seinen Expertenpool um Z Zero-computation Experts zusätzlich zu den N Standard-FFN-Experten. Zero-computation Experts geben die Eingabe unverändert als Ausgabe zurück und verursachen daher keinen zusätzlichen Rechenaufwand.
Das MoE-Modul in LongCat-Flash lässt sich wie folgt formalisieren:
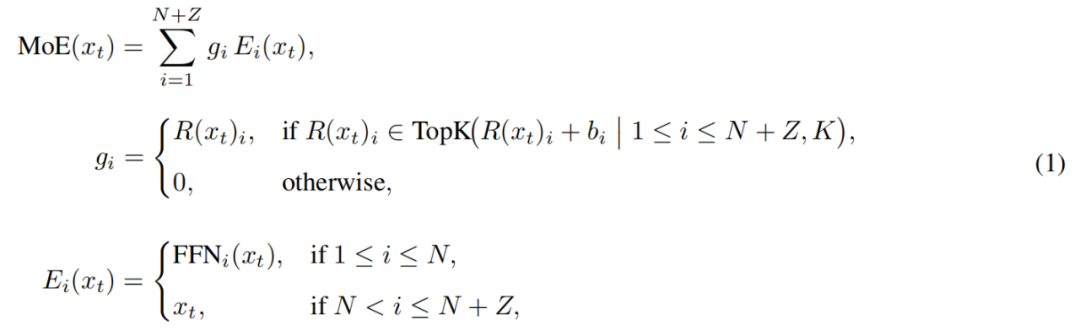
Hierbei ist x_t das t-te Token der Eingabesequenz, R steht für den Softmax-Router, b_i für den Bias des i-ten Experten und K für die Anzahl der für jedes Token ausgewählten Experten. Der Router weist jedem Token K Experten zu, wobei die Anzahl der aktivierten FFN-Experten je nach Kontextbedeutung des Tokens variiert. Durch diesen adaptiven Mechanismus kann das Modell für kontextuell wichtigere Tokens mehr Rechenressourcen zuweisen und so bei gleichem Rechenaufwand eine bessere Leistung erzielen (siehe Abbildung 3a).
Außerdem muss das Modell beim Verarbeiten der Eingabe lernen, je nach Bedeutung des Tokens zu entscheiden, ob mehr Rechenressourcen eingesetzt werden sollen. Ohne Kontrolle der Auswahlhäufigkeit von Zero-computation Experts könnte das Modell dazu neigen, nur rechenintensive Experten zu wählen und Zero-computation Experts zu vernachlässigen, was zu ineffizienter Ressourcennutzung führt.
Um dieses Problem zu lösen, hat Meituan den Experten-Bias-Mechanismus der aux-loss-free-Strategie verbessert: Es wurde ein experten-spezifischer Bias eingeführt, der die Routing-Scores dynamisch an die jüngste Nutzung der Experten anpasst und dabei vom Trainingsziel des Sprachmodells entkoppelt bleibt.
Die Aktualisierungsregel verwendet einen PID-Controller aus der Regelungstechnik, um den Experten-Bias in Echtzeit feinzujustieren. Dadurch müssen beim Verarbeiten jedes Tokens nur 18.6 bis 31.3 Milliarden (im Schnitt etwa 27 Milliarden) Parameter aktiviert werden, was eine optimierte Ressourcenzuteilung ermöglicht.
Shortcut-connected MoE
Ein weiteres Highlight von LongCat-Flash ist der Shortcut-connected MoE-Mechanismus.
Im Allgemeinen wird die Effizienz großskaliger MoE-Modelle stark durch Kommunikationsaufwand begrenzt. In traditionellen Ausführungsparadigmen führt Expertenparallelität zu einem sequentiellen Workflow: Zuerst müssen Tokens durch eine globale Kommunikationsoperation an die zugewiesenen Experten verteilt werden, bevor die Berechnung beginnen kann.
Diese Reihenfolge – erst Kommunikation, dann Berechnung – verursacht zusätzliche Wartezeiten, insbesondere im großskaligen verteilten Training, wo Kommunikationslatenz zum Flaschenhals wird.
Frühere Forscher versuchten, das Problem durch Shared-Expert-Architekturen zu lösen, indem sie Kommunikation und Berechnung einzelner Experten überlappten, aber deren Effizienz war durch das kleine Berechnungsfenster einzelner Experten begrenzt.
Meituan überwindet diese Einschränkung durch die Einführung der ScMoE-Architektur. ScMoE bringt eine Shortcut-Verbindung zwischen den Schichten ein, sodass die Berechnung des dichten FFN der vorherigen Schicht parallel zur Verteilung/Aggregation der Kommunikation der aktuellen MoE-Schicht ausgeführt werden kann. Im Vergleich zu Shared-Expert-Architekturen entsteht so ein größeres Überlappungsfenster zwischen Kommunikation und Berechnung.
Dieses Architekturdesign wurde in mehreren Experimenten validiert.
Erstens beeinträchtigt das ScMoE-Design nicht die Modellqualität. Wie in Abbildung 4 zu sehen ist, sind die Trainingsverlustkurven von ScMoE und der Baseline ohne ScMoE nahezu identisch, was beweist, dass diese Umstrukturierung die Modellleistung nicht beeinträchtigt. Dieses Ergebnis wurde in verschiedenen Konfigurationen konsistent bestätigt.
Wichtiger ist, dass diese Ergebnisse zeigen: Die Stabilität und Leistungsfähigkeit von ScMoE ist orthogonal zur Wahl des Attention-Mechanismus (d.h. unabhängig davon, welcher Attention-Mechanismus verwendet wird, bleiben Stabilität und Nutzen erhalten).
Zweitens bietet die ScMoE-Architektur erhebliche systemseitige Effizienzsteigerungen für Training und Inferenz. Konkret zeigt sich dies in:
Großskaliges Training: Das erweiterte Überlappungsfenster ermöglicht es, die Berechnung der vorherigen Blöcke vollständig parallel zur Verteilung und Aggregation in der MoE-Schicht auszuführen, indem die Operationen entlang der Token-Dimension in feingranulare Blöcke unterteilt werden.
Effiziente Inferenz: ScMoE unterstützt Single-Batch-Overlap-Pipelines und reduziert im Vergleich zu führenden Modellen wie DeepSeek-V3 die theoretische Token-per-Output-Time (TPOT) um fast 50%. Noch wichtiger: Es ermöglicht die gleichzeitige Ausführung verschiedener Kommunikationsmodi – die Intra-Node-Tensor-Parallel-Kommunikation auf dem dichten FFN (über NVLink) kann vollständig mit der Inter-Node-Expertenkommunikation (über RDMA) überlappen, was die Gesamtnetzwerkauslastung maximiert.
Kurz gesagt: ScMoE bietet erhebliche Leistungssteigerungen, ohne die Modellqualität zu beeinträchtigen.
Modellerweiterungsstrategie und mehrstufiges Training
Meituan hat außerdem eine effiziente Modellerweiterungsstrategie vorgeschlagen, die die Leistung bei zunehmender Modellgröße deutlich verbessert.
Erstens Hyperparameter-Transfer: Beim Training extrem großer Modelle ist das direkte Ausprobieren verschiedener Hyperparameter-Kombinationen sehr teuer und instabil. Daher experimentiert Meituan zunächst mit kleineren Modellen, um die besten Hyperparameter zu finden, und überträgt diese dann auf das große Modell. Das spart Kosten und sichert die Leistung. Die Transferregeln sind in Tabelle 1 dargestellt:
Zweitens Model Growth Initialization: Meituan startet mit einem halb so großen Modell, das bereits auf mehreren zehn Milliarden Tokens vortrainiert wurde, speichert einen Checkpoint und erweitert dann auf die volle Größe, um das Training fortzusetzen.
Mit dieser Methode zeigt das Modell eine typische Verlustkurve: Der Verlust steigt kurz an, konvergiert dann schnell und ist letztlich deutlich besser als die zufällige Initialisierung. Abbildung 5b zeigt ein repräsentatives Ergebnis aus dem 6B-Aktivierungsparameter-Experiment und verdeutlicht den Vorteil der Model Growth Initialization.
Drittens ein mehrschichtiges Stabilitätskit: Meituan verbessert die Trainingsstabilität von LongCat-Flash in Bezug auf Router-Stabilität, Aktivierungsstabilität und Optimizer-Stabilität.
Viertens deterministische Berechnung: Diese Methode gewährleistet vollständige Reproduzierbarkeit der Ergebnisse und ermöglicht die Erkennung von Silent Data Corruption (SDC) während des Trainings.
Durch diese Maßnahmen bleibt das Training von LongCat-Flash stets hochstabil, ohne dass es zu nicht wiederherstellbaren Verlustspitzen kommt.
Auf Basis der Trainingsstabilität hat Meituan zudem eine durchdachte Trainingspipeline entwickelt, die LongCat-Flash fortschrittliche Agentenfähigkeiten verleiht. Der Prozess umfasst großangelegtes Pretraining, Midterm-Training für Reasoning- und Code-Fähigkeiten sowie ein nachgelagertes Training, das sich auf Dialog und Tool-Nutzung konzentriert.
In der Anfangsphase wird ein Basismodell aufgebaut, das besser für das nachgelagerte Agenten-Training geeignet ist. Dafür hat Meituan eine zweistufige Pretraining-Datenfusionsstrategie entwickelt, um sich auf datenintensive Reasoning-Bereiche zu konzentrieren.
In der mittleren Trainingsphase werden die Reasoning- und Code-Fähigkeiten weiter gestärkt; gleichzeitig wird die Kontextlänge auf 128k erweitert, um den Anforderungen des nachgelagerten Agenten-Trainings gerecht zu werden.
Schließlich folgt ein mehrstufiges nachgelagertes Training. Da hochwertige und schwierige Trainingsdaten im Agentenbereich rar sind, hat Meituan ein Multi-Agenten-Synthese-Framework entwickelt: Dieses definiert die Aufgabenkomplexität entlang der Dimensionen Informationsverarbeitung, Tool-Komplexität und Nutzerinteraktion und verwendet spezialisierte Controller, um komplexe Aufgaben mit iterativem Reasoning und Umweltinteraktion zu generieren.
Dieses Design sorgt dafür, dass das Modell bei komplexen Aufgaben, die Tool-Aufrufe und Umweltinteraktionen erfordern, hervorragend abschneidet.
Schnell und günstig im Betrieb
Wie schafft das LongCat-Flash?
Wie bereits erwähnt, kann LongCat-Flash auf einer H800-GPU mit über 100 Tokens pro Sekunde inferieren, bei Kosten von nur 0,7 US-Dollar pro Million ausgegebener Tokens – also schnell und günstig.
Wie wird das erreicht? Erstens durch eine mit der Modellarchitektur abgestimmte parallele Inferenzarchitektur; zweitens durch Optimierungen wie Quantisierung und benutzerdefinierte Kernels.
Spezielle Optimierungen: Das Modell läuft „von selbst reibungslos“
Um ein effizientes Inferenzsystem zu bauen, müssen zwei Schlüsselprobleme gelöst werden: die Koordination von Berechnung und Kommunikation sowie das Lesen, Schreiben und Speichern des KV-Caches.
Für die erste Herausforderung nutzen bestehende Methoden üblicherweise Parallelität auf drei Ebenen: Operator-, Experten- und Schichtebene. Die ScMoE-Architektur von LongCat-Flash führt eine vierte Ebene ein – die Modulüberlappung. Dafür hat das Team die SBO (Single Batch Overlap) Scheduling-Strategie entwickelt, um Latenz und Durchsatz zu optimieren.
SBO ist eine vierstufige Pipeline-Ausführung, die das Potenzial von LongCat-Flash durch Modulüberlappung voll ausschöpft (siehe Abbildung 9). Im Unterschied zu TBO wird der Kommunikationsaufwand innerhalb eines einzelnen Batches versteckt. In der ersten Phase wird die MLA-Berechnung ausgeführt, die die Eingabe für die folgenden Phasen liefert; in der zweiten Phase werden Dense FFN und Attn 0 (QKV-Projektion) mit der all-to-all-Dispatch-Kommunikation überlappt; in der dritten Phase wird MoE GEMM unabhängig ausgeführt, wobei die Latenz von der breiten EP-Deployment-Strategie profitiert; in der vierten Phase werden Attn 1 (Kernattention und Output-Projektion) sowie Dense FFN mit all-to-all-Combine überlappt. Dieses Design reduziert effektiv den Kommunikationsaufwand und gewährleistet eine effiziente Inferenz von LongCat-Flash.
Für die zweite Herausforderung – das Lesen, Schreiben und Speichern des KV-Caches – löst LongCat-Flash diese Probleme durch Innovationen in der Attention-Mechanik und der MTP-Struktur, um den effektiven I/O-Aufwand zu reduzieren.
Zunächst die Beschleunigung durch speculative decoding. LongCat-Flash verwendet MTP als Draft-Modell und optimiert anhand einer Systemanalyse der Beschleunigungsformel für speculative decoding drei Schlüsselfaktoren: erwartete Akzeptanzlänge, Kostenverhältnis zwischen Draft- und Zielmodell sowie Kostenverhältnis zwischen Zielverifikation und Decodierung. Durch die Integration eines einzelnen MTP-Heads und die Einführung in der späten Pretraining-Phase wird eine Akzeptanzrate von etwa 90% erreicht. Um Qualität und Geschwindigkeit des Drafts auszubalancieren, wird eine leichte MTP-Architektur mit weniger Parametern verwendet, während die C2T-Methode ein Klassifikationsmodell nutzt, um wenig wahrscheinliche Tokens herauszufiltern.
Als nächstes die KV-Cache-Optimierung, umgesetzt durch die 64-Head-Attention-Mechanik von MLA. MLA hält die Balance zwischen Leistung und Effizienz, reduziert die Rechenlast deutlich und ermöglicht eine hervorragende KV-Cache-Kompression, wodurch Speicher- und Bandbreitenbedarf sinken. Das ist entscheidend für die Koordination der Pipeline von LongCat-Flash, da das Modell immer Attention-Berechnungen hat, die nicht mit der Kommunikation überlappen können.
Systemseitige Optimierung: Hardware als „Teamplayer“
Um Scheduling-Overhead zu minimieren, hat das LongCat-Flash-Team das launch-bound-Problem gelöst, das durch Kernel-Start-Overhead im LLM-Inferenzsystem verursacht wird. Besonders nach Einführung von speculative decoding entstehen durch unabhängiges Scheduling von Verifikations- und Draft-Forward-Kernel erhebliche Overheads. Mit der TVD-Fusion-Strategie werden Ziel-Forward, Verifikation und Draft-Forward in einem einzigen CUDA-Graph zusammengefasst. Um die GPU-Auslastung weiter zu erhöhen, wurde ein Overlap-Scheduler implementiert, der in einer Scheduling-Iteration mehrere Forward-Schritte startet und so CPU-Scheduling- und Synchronisationsaufwand effektiv versteckt.
Benutzerdefinierte Kernel-Optimierungen adressieren die durch die autoregressive Natur der LLM-Inferenz verursachten Effizienzprobleme. Die Prefill-Phase ist rechenintensiv, während die Decodierphase aufgrund der Traffic-Muster oft speichergebunden ist. Für MoE GEMM wird die SwapAB-Technik verwendet, bei der das Gewicht als linke Matrix und die Aktivierung als rechte Matrix betrachtet wird, um mit der Flexibilität der 8-Element-Granularität in der n-Dimension die Tensor-Core-Auslastung zu maximieren. Kommunikationskernel nutzen die hardwarebeschleunigte Broadcast- und In-Switch-Reduction-Funktion von NVLink Sharp, um Datenbewegungen und SM-Auslastung zu minimieren und übertreffen mit nur 4 Thread-Blocks im Bereich von 4KB bis 96MB Nachrichtengröße durchgehend NCCL und MSCCL++.
Bei der Quantisierung verwendet LongCat-Flash das gleiche feingranulare Blockquantisierungsschema wie DeepSeek-V3. Um das beste Verhältnis zwischen Leistung und Genauigkeit zu erzielen, wird eine schichtweise gemischte Präzisionsquantisierung auf Basis zweier Schemata implementiert: Das erste identifiziert lineare Schichten (insbesondere Downproj) mit Eingabeaktivierungen von bis zu 10^6; das zweite berechnet blockweise FP8-Quantisierungsfehler pro Schicht und findet signifikante Fehler in bestimmten Experten-Schichten. Durch die Schnittmenge beider Schemata wird eine signifikante Genauigkeitssteigerung erzielt.
Praxistest: Wie schnell und günstig ist es wirklich?
Die gemessene Leistung zeigt, dass LongCat-Flash in verschiedenen Konfigurationen hervorragend abschneidet. Im Vergleich zu DeepSeek-V3 erreicht LongCat-Flash bei ähnlicher Kontextlänge höheren Durchsatz und schnellere Generierung.
In Agent-Anwendungen, bei denen zwischen Inferenzinhalten (für Nutzer sichtbar, muss mit menschlicher Lesegeschwindigkeit von etwa 20 Tokens/s mithalten) und Aktionsbefehlen (für Nutzer unsichtbar, beeinflussen aber direkt die Startzeit von Tool-Aufrufen und erfordern maximale Geschwindigkeit) unterschieden wird, hält LongCat-Flash mit seiner nahezu 100 Tokens/s Generierungsgeschwindigkeit die Verzögerung pro Tool-Aufruf unter 1 Sekunde und steigert so die Interaktivität von Agent-Anwendungen erheblich. Bei einem angenommenen Preis von 2 US-Dollar pro Stunde für eine H800-GPU bedeutet das Kosten von 0,7 US-Dollar pro Million ausgegebener Tokens.
Theoretische Leistungsanalysen zeigen, dass die Latenz von LongCat-Flash hauptsächlich von drei Komponenten abhängt: MLA, all-to-all dispatch/combine und MoE. Bei EP=128, batch=96 pro Karte und MTP-Akzeptanzrate ≈80% liegt das theoretische TPOT-Limit von LongCat-Flash bei 16ms, deutlich besser als DeepSeek-V3 mit 30ms und Qwen3-235B-A22B mit 26,2ms. Bei 2 US-Dollar pro Stunde für eine H800-GPU liegen die Ausgabekosten von LongCat-Flash bei 0,09 US-Dollar pro Million Tokens, weit unter den 0,17 US-Dollar von DeepSeek-V3. Diese Werte sind jedoch nur theoretische Maxima.
Wir haben auch die kostenlose Testseite von LongCat-Flash ausprobiert.
Zuerst haben wir das Modell gebeten, einen etwa 1000 Wörter langen Aufsatz über den Herbst zu schreiben.
Kaum hatten wir die Anfrage gestellt und die Bildschirmaufnahme gestartet, hatte LongCat-Flash die Antwort schon geschrieben – wir konnten die Aufnahme gar nicht rechtzeitig stoppen.
Bei genauerem Hinsehen fällt auf, dass die Ausgabe des ersten Tokens bei LongCat-Flash besonders schnell ist. Bei anderen Chat-Modellen muss man oft warten, was die Geduld auf die Probe stellt – wie wenn man dringend eine WeChat-Nachricht lesen will, das Handy aber „Empfang läuft“ anzeigt. LongCat-Flash ändert dieses Erlebnis: Die Verzögerung beim ersten Token ist praktisch nicht spürbar.
Auch die Geschwindigkeit der nachfolgenden Token-Generierung ist sehr hoch und übertrifft die menschliche Lesegeschwindigkeit deutlich.
Als nächstes haben wir die „Online-Suche“ aktiviert, um zu sehen, wie schnell LongCat-Flash in dieser Disziplin ist. Wir baten LongCat-Flash, gute Restaurants in der Nähe von Wangjing zu empfehlen.
Im Test war deutlich zu spüren, dass LongCat-Flash nicht erst lange „nachdenkt“, sondern fast sofort antwortet. Auch die Online-Suche fühlt sich „schnell“ an. Zudem liefert es beim schnellen Output auch Quellenangaben, was die Glaubwürdigkeit und Nachvollziehbarkeit der Informationen sichert.
Wer das Modell herunterladen kann, sollte es lokal ausprobieren und sehen, ob die Geschwindigkeit von LongCat-Flash ebenso beeindruckend ist.
Wenn große Modelle in die Praxis einziehen
In den letzten Jahren hat man bei jedem neuen großen Modell gefragt: Wie sind die Benchmark-Daten? Wie viele Rankings wurden gebrochen? Ist es SOTA? Heute hat sich das geändert. Bei vergleichbarer Leistungsfähigkeit interessiert vielmehr: Ist das Modell teuer? Wie schnell ist es? Besonders bei Unternehmen und Entwicklern, die Open-Source-Modelle nutzen, ist das offensichtlich. Viele Nutzer setzen Open-Source-Modelle ein, um die Abhängigkeit und Kosten von Closed-Source-APIs zu senken, weshalb sie besonders sensibel auf Rechenbedarf, Inferenzgeschwindigkeit und Quantisierungseffekte reagieren.
Das Open-Source-Modell LongCat-Flash von Meituan ist ein Paradebeispiel für diesen Trend. Der Fokus liegt darauf, große Modelle wirklich erschwinglich und schnell nutzbar zu machen – ein Schlüssel zur technischen Verbreitung.
Diese pragmatische Ausrichtung entspricht auch dem bisherigen Eindruck von Meituan. In der Vergangenheit wurden die meisten technischen Investitionen genutzt, um reale Geschäftsprobleme zu lösen – etwa das 2022 mit dem ICRA Best Navigation Paper ausgezeichnete EDPLVO, das für Drohnenlieferungen bei Signalverlust durch dichte Bebauung entwickelt wurde; oder der kürzlich mitentwickelte globale ISO-Standard für Drohnenhindernisvermeidung, der auf Erfahrungen mit Hindernissen wie Drachenleinen und Fensterputzerseilen basiert. Das nun veröffentlichte LongCat-Flash ist das Modell hinter dem KI-Programmierwerkzeug „NoCode“, das sowohl intern als auch extern kostenlos genutzt werden kann, um „vibe coding“ zu fördern und Kosten zu senken sowie Effizienz zu steigern.
Dieser Wandel vom Performance-Wettlauf hin zur Praxisorientierung spiegelt die natürliche Entwicklung der KI-Branche wider. Wenn die Modellfähigkeiten sich angleichen, werden technische Effizienz und Bereitstellungskosten zum entscheidenden Unterscheidungsmerkmal. Die Open-Source-Veröffentlichung von LongCat-Flash ist nur ein Beispiel für diesen Trend, bietet der Community aber einen wertvollen technischen Ansatz: Wie kann man bei gleichbleibender Modellqualität durch Architekturinnovationen und Systemoptimierung die Einstiegshürde senken? Für Entwickler und Unternehmen mit begrenztem Budget, die dennoch fortschrittliche KI nutzen möchten, ist das zweifellos wertvoll.
Haftungsausschluss: Der Inhalt dieses Artikels gibt ausschließlich die Meinung des Autors wieder und repräsentiert nicht die Plattform in irgendeiner Form. Dieser Artikel ist nicht dazu gedacht, als Referenz für Investitionsentscheidungen zu dienen.
Das könnte Ihnen auch gefallen
ETH übernimmt die Bühne: Der wahre Beginn der zweiten Hälfte des Bullenmarktes
Basierend auf der Analyse der Marktstruktur, Kapitalflüsse, On-Chain-Daten sowie des regulatorischen Umfelds ist unser Urteil eindeutig: Ethereum übernimmt schrittweise die Rolle von Bitcoin und wird zum Kernvermögenswert in der zweiten Hälfte des Bullenmarktes.

BTC-Strategien im Zeitalter leistungsstarker öffentlicher Blockchains: Die Transformation durch Solana und On-Chain-Kapital
Im Zeitalter der Hochleistungs-Blockchains besteht der Wettbewerb letztlich nicht nur in einem reinen TPS-Wettlauf, sondern darin, wer ein aktiveres und effizienteres On-Chain-Wirtschaftsökosystem aufbauen kann.

WLFI strategisch inkubiert BlockRock und schafft eine neue Antriebskraft für RWA-Finanzderivate
Diese Zusammenarbeit markiert nicht nur die tiefgehende Positionierung von WLFI im RWA-Sektor, sondern etabliert auch BlockRock als die zentrale RWA-Plattform im Ökosystem.

Unternehmen gehen ins Ausland: Architekturwahl und Strategien zur Steueroptimierung
Wie wichtig ist eine geeignete Unternehmensstruktur?
