
Vitalik:グルーおよびコプロセッサーアーキテクチャ、効率とセキュリティを向上させる新しい構想

グルーは優れたグルーとなるように最適化されるべきであり、コプロセッサーもまた優れたコプロセッサーとなるように最適化されるべきです。
グルー(glue)は良いグルーとなるよう最適化されるべきであり、コプロセッサー(coprocessor)も良いコプロセッサーとなるよう最適化されるべきです。
原題:《Glue and coprocessor architectures》
著者:Vitalik Buterin、Ethereum創設者
翻訳:Deng Tong、Jinse Finance
特に、Justin Drake、Georgios Konstantopoulos、Andrej Karpathy、Michael Gao、Tarun Chitra、および様々なFlashbotsの貢献者からのフィードバックとコメントに感謝します。
現代世界で行われているあらゆるリソース集約型計算を中程度の詳細で分析すると、何度も見られる特徴があります。それは、計算が2つの部分に分けられるということです:
- 比較的少量だが複雑で計算量の少ない「ビジネスロジック」
- 大量で集中的だが高度に構造化された「高コストな作業」
この2種類の計算形式は、異なる方法で処理するのが最適です。前者は、効率が低くても非常に高い汎用性が必要なアーキテクチャが求められます。後者は、汎用性は低くても非常に高い効率が必要です。
実際にこのような異なる方法の例は?
まず、私が最もよく知っている環境、Ethereum Virtual Machine(EVM)について見てみましょう。これは、最近私がEthereumで行った取引のgethデバッグトレースです。ENSで自分のブログのIPFSハッシュを更新しました。この取引は合計で46924ガスを消費し、以下のように分類できます:
- 基本コスト:21,000
- コールデータ:1,556
- EVM実行:24,368
- SLOADオペコード:6,400
- SSTOREオペコード:10,100
- LOGオペコード:2,149
- その他:6,719

ENSハッシュ更新のEVMトレース。下から2番目の列がガス消費量です。
この話の教訓は、実行の大部分(EVMだけを見ると約73%、計算をカバーする基本コスト部分も含めると約85%)が、非常に少数の構造化された高コストな操作、つまりストレージの読み書き、ログ、暗号化に集中しているということです(基本コストには署名検証のための3000が含まれ、EVMにはハッシュのための272も含まれます)。残りの実行は「ビジネスロジック」です。たとえば、calldataのビットを交換して設定しようとしているレコードのIDや設定するハッシュを抽出するなどです。トークン転送では、残高の加算や減算が含まれ、より高度なアプリケーションではループなどが含まれる場合もあります。
EVMでは、この2種類の実行形式は異なる方法で処理されます。高度なビジネスロジックは、通常Solidityなどの高級言語で記述され、EVMにコンパイルされます。高コストな作業はEVMオペコード(SLOADなど)によってトリガーされますが、実際の計算の99%以上は、クライアントコード(あるいはライブラリ)内部で直接記述された専用モジュールで行われます。
このパターンへの理解を深めるために、別の文脈、torchを使ったPythonによるAIコードで探ってみましょう。
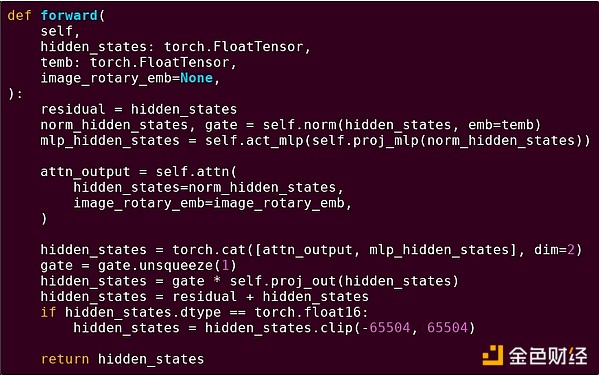
トランスフォーマーモデルのブロックのフォワードパス
ここで何が見えるでしょうか?Pythonで記述された比較的少量の「ビジネスロジック」が、実行される操作の構造を記述しています。実際には、入力の取得方法や出力に対して行う操作などの詳細を決定する別のタイプのビジネスロジックも存在します。しかし、各操作自体(self.norm、torch.cat、+、*、self.attn内部の各ステップなど)を掘り下げると、ベクトル化された計算、つまり同じ操作が大量の値に対して並列に計算されていることがわかります。最初の例と同様に、計算のごく一部がビジネスロジックに使われ、大部分は大規模な構造化された行列やベクトル演算の実行に使われています。実際、そのほとんどは行列の乗算です。
EVMの例と同様に、この2種類の作業は異なる方法で処理されます。高度なビジネスロジックコードはPythonで記述されており、非常に汎用的で柔軟ですが非常に遅いです。私たちは、総計算コストのごく一部しか関与しないため、非効率性を受け入れています。一方、集中的な操作は高度に最適化されたコードで記述され、通常はGPU上で動作するCUDAコードです。最近では、LLM推論がASIC上で行われるケースも増えています。
現代のプログラマブル暗号学、たとえばSNARKも、2つのレベルで同様のパターンに従っています。まず、プローバーは高級言語で記述でき、重い作業は上記のAI例のようにベクトル化された操作で行われます。ここでの円形STARKコードがそれを示しています。次に、暗号学内部で実行されるプログラム自体も、汎用ビジネスロジックと高度に構造化された高コストな作業の間で分割できるように記述できます。
その仕組みを理解するために、STARK証明の最新トレンドの1つを見てみましょう。汎用性と使いやすさのために、チームは広く採用されている最小限の仮想マシン(RISC-Vなど)向けにSTARKプローバーを構築することが増えています。実行を証明する必要があるプログラムはすべてRISC-Vにコンパイルでき、プローバーはそのコードのRISC-V実行を証明できます。
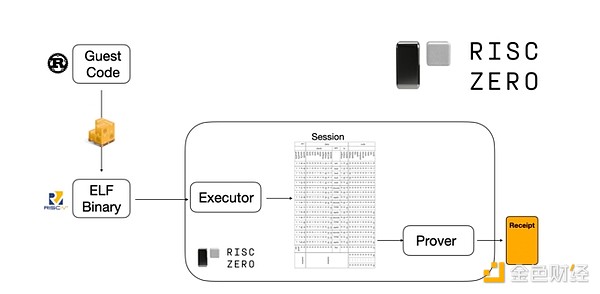
RiscZeroドキュメントからの図
これは非常に便利です。つまり、証明ロジックを一度書くだけで、以降はあらゆる「従来型」プログラミング言語(たとえばRiskZeroはRustをサポート)で証明が必要なプログラムを書けます。しかし、問題もあります。この方法は大きなオーバーヘッドを生みます。プログラマブル暗号はすでに非常に高コストです。RISC-Vインタプリタでコードを実行するオーバーヘッドは大きすぎます。そこで開発者は工夫を考えました。計算の大部分を占める特定の高コストな操作(通常はハッシュや署名)を特定し、それらの操作を非常に効率的に証明する専用モジュールを作成します。そして、非効率だが汎用的なRISC-V証明システムと効率的だが専門的な証明システムを組み合わせることで、両方の利点を得られるのです。
ZK-SNARK以外のプログラマブル暗号、たとえばマルチパーティ計算(MPC)や完全同型暗号(FHE)でも、同様の方法で最適化が行われる可能性があります。
全体として、この現象はどのようなものか?
現代の計算は、私が「グルーとコプロセッサーアーキテクチャ」と呼ぶものにますます従っています。つまり、中央に高い汎用性を持つが効率の低い「グルー」コンポーネントがあり、1つまたは複数のコプロセッサーコンポーネント間でデータを転送します。コプロセッサーは汎用性は低いが効率は高いです。
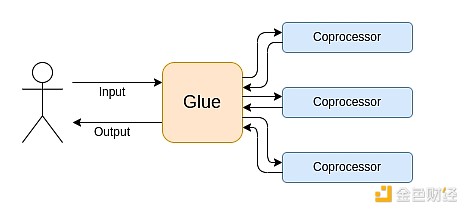
これは単純化です。実際には、効率と汎用性のトレードオフ曲線には通常2つ以上のレイヤーがあります。GPUや業界で一般的に「コプロセッサー」と呼ばれるチップは、CPUほど汎用的ではありませんが、ASICよりは汎用的です。専門化の度合いのトレードオフは複雑で、どのアルゴリズムの部分が5年後も変わらず、どの部分が6か月後に変わるかという予測や直感に依存します。ZK証明アーキテクチャでも、同様の多層的な専門化がよく見られます。しかし、広範な思考モデルとしては、2つのレイヤーを考えるだけで十分です。多くの計算分野で同様の状況が見られます:
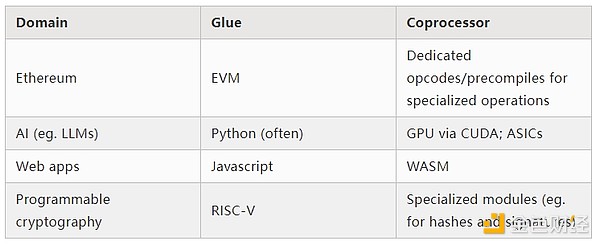
上記の例から、計算は確かにこのように分割できることがわかります。これは自然法則のように思えます。実際、数十年にわたり計算の専門化の例が見られます。しかし、私はこの分離が増加していると考えています。それには理由があります:
私たちは最近になって、CPUクロック速度の向上の限界に達しました。そのため、さらなる利益を得るには並列化しかありません。しかし、並列化は推論が難しいため、開発者にとっては順次推論を続け、並列化はバックエンドで発生し、特定の操作のために構築された専用モジュールにラップされる方が実際的です。
計算速度は最近になって非常に速くなり、ビジネスロジックの計算コストは本当に無視できるほどになりました。この世界では、ビジネスロジック実行のVMを計算効率以外の目標、たとえば開発者フレンドリーさ、親しみやすさ、安全性などのために最適化することも意味があります。一方、専用の「コプロセッサー」モジュールは効率のために設計され続け、グルーとの比較的単純な「インターフェース」から安全性や開発者フレンドリーさを得られます。
最も重要な高コストな操作が何かがますます明確になっています。これは暗号学で最も顕著で、どのタイプの特定の高コストな操作が最も使われるかが明らかです:モジュラー演算、楕円曲線線形結合(いわゆるマルチスカラー乗算)、高速フーリエ変換など。AIでも同様で、20年以上にわたり計算の大部分は「主に行列乗算」(精度レベルは異なりますが)です。他の分野でも同様の傾向が見られます。20年前と比べて、(計算集約型の)計算における未知の未知数ははるかに少なくなっています。
これは何を意味するのか?
重要なポイントは、グルー(Glue)は良いグルーとなるよう最適化されるべきであり、コプロセッサー(coprocessor)も良いコプロセッサーとなるよう最適化されるべきだということです。これが意味するところを、いくつかの重要な分野で探ってみましょう。
EVM
ブロックチェーン仮想マシン(EVMなど)は効率的である必要はなく、親しみやすければ十分です。正しいコプロセッサー(いわゆる「プリコンパイル」)を追加するだけで、非効率なVMでの計算も、ネイティブで効率的なVMでの計算と同じくらい効率的にできます。たとえば、EVMの256ビットレジスタによるオーバーヘッドは比較的小さく、EVMの親しみやすさや既存の開発者エコシステムの恩恵は非常に大きく持続的です。EVMを最適化する開発チームは、並列化の欠如がスケーラビリティの主な障害ではないことも発見しています。
EVMを改良する最良の方法は、おそらく(i)より良いプリコンパイルや専用オペコードを追加すること(たとえばEVM-MAXやSIMDの組み合わせなど)、および(ii)ストレージレイアウトの改良です。たとえば、Verkleツリーの変更は副次的に、隣接するストレージスロットへのアクセスコストを大幅に下げます。
Ethereum Verkleツリー提案のストレージ最適化。隣接するストレージキーをまとめて配置し、ガスコストをそれに合わせて調整しています。このような最適化とより良いプリコンパイルは、EVM自体を調整するよりも重要かもしれません。
セキュアコンピューティングとオープンハードウェア
現代計算のセキュリティをハードウェアレベルで高める大きな課題は、その複雑さと専有性にあります。チップは効率的に設計されており、それには専有的な最適化が必要です。バックドアは簡単に隠せ、サイドチャネル脆弱性も次々と発見されています。
人々は、よりオープンで安全な代替案を複数の観点から推進し続けています。一部の計算は、信頼できる実行環境、たとえばユーザーのスマートフォン上でますます行われるようになり、ユーザーのセキュリティが向上しています。よりオープンソースな消費者向けハードウェアを推進する動きも続いており、最近ではUbuntuが動作するRISC-Vノートパソコンなどの成果もあります。
Debianが動作するRISC-Vノートパソコン
しかし、効率は依然として課題です。上記リンク記事の著者はこう書いています:
RISC-Vなどの新しいオープンソースチップ設計は、すでに存在し数十年改良されてきたプロセッサ技術と競うことはできません。進歩には必ず出発点があります。
FPGA上にRISC-Vコンピュータを構築するこのような偏執的なアイデアは、さらに大きなオーバーヘッドに直面します。しかし、グルーとコプロセッサーアーキテクチャによって、このオーバーヘッドが実際には重要でなくなるとしたらどうでしょうか?オープンで安全なチップは専有チップより遅くてもよいと受け入れ、必要なら投機的実行や分岐予測などの一般的な最適化も放棄し、その代わりに最も集中的な特定タイプの計算用に(必要なら専有の)ASICモジュールを追加することで補うとしたらどうでしょうか?センシティブな計算は「メインチップ」で行い、これはセキュリティ、オープン設計、サイドチャネル耐性を最適化します。より集中的な計算(たとえばZK証明やAI)はASICモジュールで行い、これらは実行される計算についてより少ない情報しか知りません(場合によっては暗号的ブラインディングによりゼロ情報も可能です)。
暗号学
もう1つの重要なポイントは、これらすべてが暗号学、特にプログラマブル暗号学の主流化に非常に楽観的な影響を与えるということです。すでにSNARK、MPC、その他の設定で、特定の高度に構造化された計算の超最適化実装が見られます。特定のハッシュ関数のオーバーヘッドは、直接計算を実行する場合と比べて数百倍しか高くなく、AI(主に行列乗算)のオーバーヘッドも非常に低いです。GKRなどのさらなる改良で、このレベルはさらに下がるかもしれません。完全に汎用的なVM実行、特にRISC-Vインタプリタでの実行は、今後も約1万倍のオーバーヘッドが続くかもしれませんが、本稿で述べた理由により、それは重要ではありません。計算の最も集中的な部分を効率的な専用技術で個別に処理すれば、全体のオーバーヘッドは制御可能です。
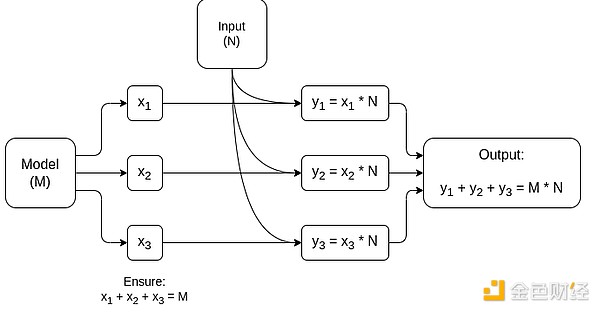
行列乗算専用MPCの簡略図。これはAIモデル推論で最大のコンポーネントです。モデルや入力のプライバシー保持方法など、詳細は本文を参照してください。
「グルーレイヤーは親しみやすければよく、効率的である必要はない」という考えの例外は、レイテンシーと、より小さな程度ではデータ帯域幅です。計算が同じデータに対して数十回繰り返される重い操作(暗号学やAIのような場合)を含む場合、非効率なグルーレイヤーによる遅延が実行時間の主なボトルネックになることがあります。したがって、グルーレイヤーにも効率要件はありますが、それらはより具体的です。
結論
全体として、私は上記の傾向が多角的に見て非常にポジティブな発展だと考えています。まず、これは開発者フレンドリーさを維持しつつ計算効率を最大化する合理的な方法であり、両方の利点をより多くの人が享受できます。特に、クライアント側で専門化を実現することで、ユーザーハードウェア上でセンシティブかつ高性能要求の計算(たとえばZK証明やLLM推論)をローカルで実行する能力が高まります。次に、効率追求が他の価値、特にセキュリティ、オープン性、シンプルさを損なわないようにする大きなチャンスを生み出します。コンピュータハードウェアのサイドチャネルセキュリティやオープン性、ZK-SNARKの回路複雑性低減、仮想マシンの複雑性低減などです。歴史的には、効率追求がこれらの要素を二の次にしてきました。グルーとコプロセッサーアーキテクチャでは、もはやそうする必要はありません。マシンの一部は効率を最適化し、もう一部は汎用性や他の価値を最適化し、両者が協調して動作します。
この傾向は暗号学にも非常に有利です。なぜなら、暗号学自体が「高コストな構造化計算」の主要な例であり、この傾向がその発展を加速させるからです。これにより、セキュリティ向上の新たな機会も生まれます。ブロックチェーンの世界でも、セキュリティ向上が可能になります。仮想マシンの最適化にあまり気を取られず、プリコンパイルや仮想マシンと共存する他の機能の最適化により注力できます。
第三に、この傾向は規模の小さい新規参入者にもチャンスを与えます。計算がよりモジュール化され、単一的でなくなることで、参入障壁が大幅に下がります。たとえば、1種類の計算用ASICでも活躍の余地があります。ZK証明分野やEVM最適化でも同様です。最先端に近い効率のコードを書くことがより簡単でアクセスしやすくなります。このようなコードの監査や形式的検証もより簡単でアクセスしやすくなります。最後に、これらの非常に異なる計算分野が共通のパターンに収束しつつあるため、分野間の協力や学習の余地が広がっています。
免責事項:本記事の内容はあくまでも筆者の意見を反映したものであり、いかなる立場においても当プラットフォームを代表するものではありません。また、本記事は投資判断の参考となることを目的としたものではありません。
こちらもいかがですか?
ビットコイン暴落の理由を解説:BTCはさらに下落するのか?
実現損失は、FTXの崩壊時以来の水準まで急増しています。Arkham Intelligenceは、初期導入者のOwen Gundenが昨年10月下旬以降、約11,000 BTC(約13億ドル)を清算したと指摘しました。暗号アナリストのAli Martinezは、週次SuperTrendが弱気に転じたと述べています。
なぜXRP保有者が突然Bitcoinの流動性危機の影響を強く感じているのか
401kにDeFiを追加:BlackRockのstaked Ethereum ETFがETHリワードへのアクセスをどのように再構築するか
