
Da tempestade de liquidações à queda na nuvem: o momento de crise da infraestrutura cripto

No dia 20, problemas na AWS da Amazon causaram a paralisação da Coinbase e de dezenas de outras principais plataformas de criptomoedas, incluindo Robinhood, Infura, Base e Solana.
Título original: Crypto Infrastructure is Far From Perfect
Autor original: YQ, KOL de cripto
Tradução original: AididiaoJP, Foresight News
Amazon Web Services sofreu novamente uma grande interrupção, impactando severamente a infraestrutura cripto. Problemas na região Leste dos EUA (centro de dados da Virgínia do Norte) da AWS causaram a paralisação da Coinbase e de dezenas de outras grandes plataformas cripto, incluindo Robinhood, Infura, Base e Solana.
A AWS reconheceu um "aumento na taxa de erros" afetando o Amazon DynamoDB e o EC2, serviços essenciais de banco de dados e computação dos quais milhares de empresas dependem. Esta interrupção fornece uma validação imediata e vívida do argumento central deste artigo: a dependência da infraestrutura cripto em provedores centralizados de serviços em nuvem cria vulnerabilidades sistêmicas que se manifestam repetidamente sob pressão.
O momento é altamente instrutivo. Apenas dez dias após um evento de liquidação em cadeia de US$ 1.93 bilhões expor falhas de infraestrutura no nível das plataformas de negociação, a interrupção da AWS de hoje mostra que o problema vai além de uma única plataforma, estendendo-se à camada fundamental da infraestrutura em nuvem. Quando a AWS falha, os efeitos em cascata atingem simultaneamente plataformas centralizadas de negociação, plataformas "descentralizadas" com dependências centralizadas e inúmeros outros serviços.
Este não é um evento isolado, mas sim um padrão. A análise a seguir documenta incidentes semelhantes de interrupção da AWS em abril de 2025, dezembro de 2021 e março de 2017, cada um levando à paralisação de serviços cripto importantes. A questão não é se a próxima falha de infraestrutura ocorrerá, mas sim quando e qual será o gatilho.
Evento de liquidação em cadeia de 10-11 de outubro de 2025: Estudo de caso
O evento de liquidação em cadeia de 10-11 de outubro de 2025 fornece um estudo de caso instrutivo sobre padrões de falha de infraestrutura. Às 20:00 UTC, um anúncio geopolítico significativo desencadeou uma liquidação em todo o mercado. Em uma hora, US$ 6 bilhões foram liquidados. Na abertura do mercado asiático, US$ 19.3 bilhões em posições alavancadas em 1.6 milhão de contas de traders haviam evaporado.
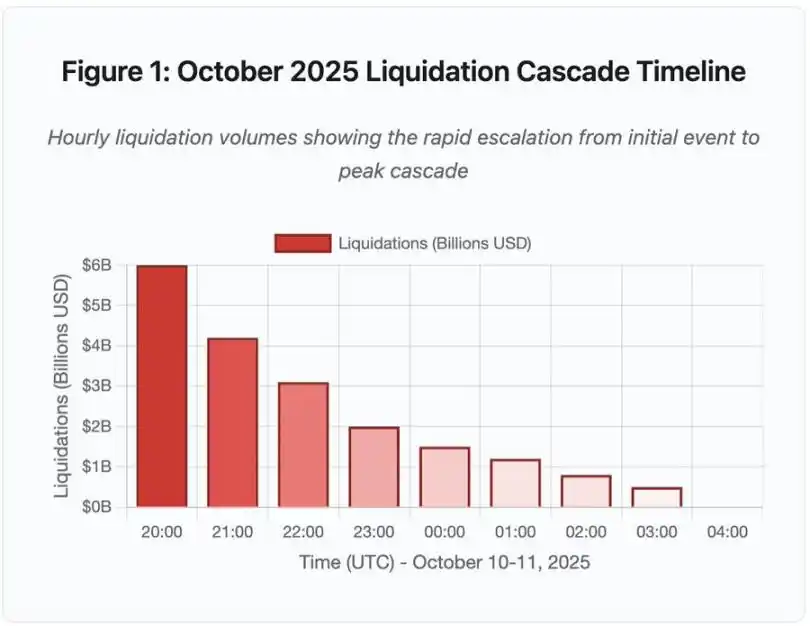
Figura 1: Linha do tempo do evento de liquidação em cadeia de outubro de 2025
Este gráfico de linha do tempo interativo mostra o progresso dramático do volume de liquidações por hora. Só na primeira hora, US$ 6 bilhões evaporaram, seguidos por uma aceleração ainda mais intensa na segunda hora. A visualização mostra:
· 20:00-21:00: Impacto inicial - US$ 6 bilhões liquidados (área vermelha)
· 21:00-22:00: Pico em cadeia - US$ 4.2 bilhões, momento em que as APIs começaram a limitar a taxa
· 22:00-04:00: Período de deterioração contínua - US$ 9.1 bilhões liquidados em um mercado de baixa liquidez
· Ponto de virada crítico: limitação de taxa de API, retirada de market makers, livro de ordens ficando raso
A escala foi pelo menos uma ordem de magnitude maior do que qualquer evento anterior no mercado cripto, e comparações históricas mostram a natureza de função degrau deste evento:
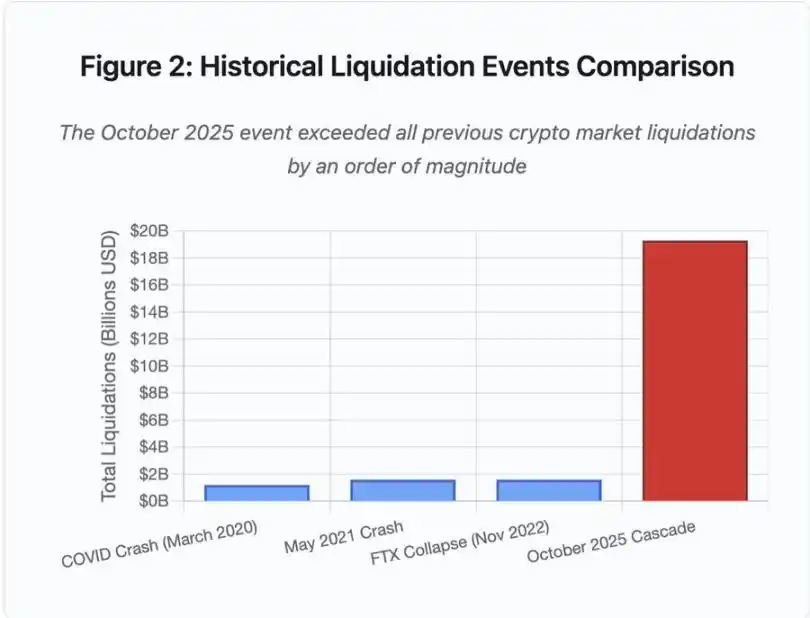
Figura 2: Comparação histórica de eventos de liquidação
O gráfico de barras ilustra dramaticamente o destaque do evento de outubro de 2025:
· Março de 2020 (COVID): US$ 1.2 bilhões
· Maio de 2021 (queda): US$ 1.6 bilhões
· Novembro de 2022 (FTX): US$ 1.6 bilhões
· Outubro de 2025: US$ 19.3 bilhões, 16 vezes maior que o recorde anterior
Mas os números de liquidação contam apenas parte da história. Questões mais interessantes dizem respeito ao mecanismo: como eventos externos de mercado desencadearam esse padrão específico de falha? A resposta revela fraquezas sistêmicas na infraestrutura das plataformas centralizadas de negociação e no design dos protocolos blockchain.
Falhas off-chain: Arquitetura das plataformas centralizadas de negociação
Sobrecarga de infraestrutura e limitação de taxa
As APIs das plataformas de negociação implementam limitação de taxa para evitar abusos e gerenciar a carga dos servidores. Durante operações normais, esses limites permitem negociações legítimas enquanto bloqueiam ataques potenciais. Durante volatilidade extrema, quando milhares de traders tentam ajustar posições simultaneamente, esses mesmos limites tornam-se gargalos.
As CEX limitam notificações de liquidação a um pedido por segundo, mesmo quando processam milhares de ordens por segundo. Durante o evento em cadeia de outubro, isso criou opacidade. Os usuários não conseguiam determinar a gravidade da cadeia em tempo real. Ferramentas de monitoramento de terceiros mostravam centenas de liquidações por minuto, enquanto as fontes oficiais mostravam muito menos.
A limitação de taxa das APIs impediu os traders de modificar posições na hora crítica inicial, pedidos de conexão expiravam, submissões de ordens falhavam. Ordens de stop loss não eram executadas, consultas de posição retornavam dados desatualizados, e esse gargalo de infraestrutura transformou um evento de mercado em uma crise operacional.
Plataformas tradicionais configuram infraestrutura para carga normal mais uma margem de segurança. Mas carga normal e carga sob estresse são radicalmente diferentes; o volume médio diário não prevê bem a demanda de pico. Durante o evento em cadeia, o volume de negociação aumentou 100 vezes ou mais, e as consultas de dados de posição aumentaram 1000 vezes, pois cada usuário verificava sua conta simultaneamente.
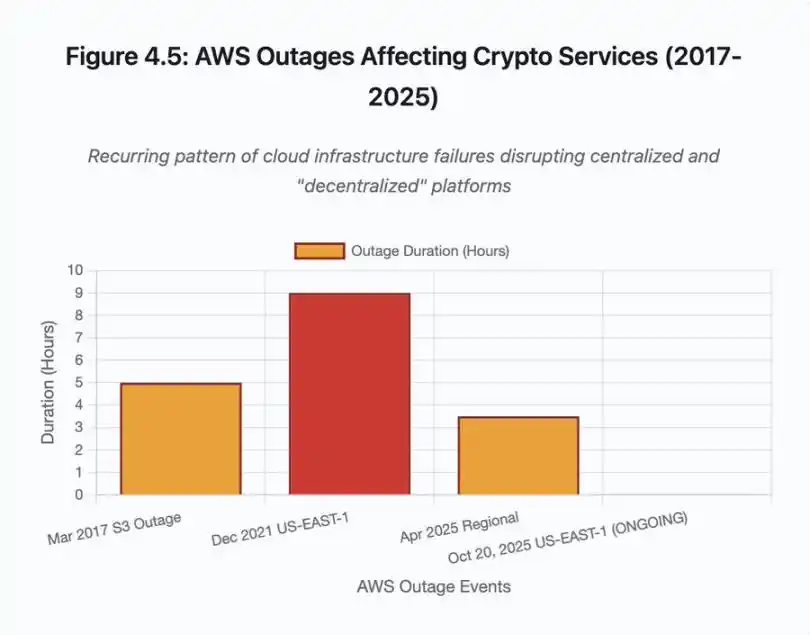
Figura 4.5: Interrupção da AWS afetando serviços cripto
Infraestrutura em nuvem com autoescalonamento ajuda, mas não responde instantaneamente; iniciar réplicas adicionais de leitura de banco de dados leva minutos. Criar novas instâncias de gateway de API leva minutos. Durante esses minutos, sistemas de margem continuam marcando o valor das posições com dados de preço corrompidos do livro de ordens sobrecarregado.
Manipulação de oráculos e falhas de precificação
Durante o evento em cadeia de outubro, uma escolha de design crítica nos sistemas de margem tornou-se evidente: algumas plataformas calculam o valor do colateral com base no preço do mercado spot interno, não em fluxos de dados de oráculos externos. Em condições normais de mercado, arbitradores mantêm a consistência de preços entre diferentes locais. Mas sob pressão de infraestrutura, esse acoplamento entra em colapso.

Figura 3: Fluxograma de manipulação de oráculos
Este fluxograma interativo visualiza cinco estágios do vetor de ataque:
· Venda inicial: pressão de venda de US$ 60 milhões em USDe
· Manipulação de preço: USDe cai de US$ 1.00 para US$ 0.65 em uma única exchange
· Falha do oráculo: sistema de margem usa fluxo de dados internos corrompidos
· Gatilho em cadeia: colaterais reavaliados para baixo, liquidações forçadas começam
· Amplificação: US$ 19.3 bilhões em liquidações (amplificação de 322x)
O ataque explorou o uso pela Binance do preço do mercado spot para colaterais sintéticos embalados. Quando o atacante despejou US$ 60 milhões de USDe em um livro de ordens relativamente raso, o preço spot caiu de US$ 1.00 para US$ 0.65. O sistema de margem, configurado para marcar colaterais pelo preço spot, reavaliou todas as posições colateralizadas em USDe para baixo em 35%. Isso desencadeou chamadas de margem e liquidações forçadas em milhares de contas.
Essas liquidações forçaram mais ordens de venda no mesmo mercado ilíquido, pressionando ainda mais o preço para baixo. O sistema de margem observou esses preços mais baixos e marcou mais posições para baixo, criando um loop de feedback que amplificou a pressão de venda de US$ 60 milhões em USDe para US$ 19.3 bilhões em liquidações forçadas.

Figura 4: Loop de feedback de liquidação em cadeia
Este gráfico de feedback ilustra a natureza auto-reforçadora da cadeia:
Queda de preço → Gatilho de liquidação → Venda forçada → Queda de preço adicional → [loop repete]
Se um sistema de oráculo bem projetado fosse usado, esse mecanismo não funcionaria. Se a Binance utilizasse um preço médio ponderado pelo tempo (TWAP) entre várias plataformas, manipulações instantâneas de preço não afetariam a avaliação do colateral. Se usassem fluxos de dados agregados de oráculos multi-fonte como Chainlink, o ataque falharia.
O evento com wBETH quatro dias antes mostrou vulnerabilidade semelhante. wBETH deveria manter uma taxa de troca 1:1 com ETH. Durante o evento em cadeia, a liquidez secou e o mercado spot wBETH/ETH mostrou um desconto de 20%. O sistema de margem reavaliou o colateral wBETH para baixo, desencadeando liquidações de posições totalmente colateralizadas por ETH subjacente.
Mecanismo de Auto-Deleverage (ADL)
Quando liquidações não podem ser executadas ao preço de mercado atual, a plataforma implementa o Auto-Deleverage (ADL), repassando perdas para traders lucrativos. O ADL fecha forçadamente posições lucrativas ao preço atual para cobrir o déficit das posições liquidadas.
Durante o evento em cadeia de outubro, a Binance executou ADL em vários pares de negociação. Traders com posições long lucrativas tiveram suas negociações fechadas à força, não por falha de gestão de risco própria, mas porque as posições de outros traders tornaram-se insolventes.
O ADL reflete uma escolha fundamental de arquitetura em derivativos centralizados. A plataforma garante que não perderá dinheiro. Isso significa que as perdas devem ser absorvidas por uma ou mais das seguintes partes:
· Fundo de seguro (reservado pela plataforma para cobrir déficits de liquidação)
· ADL (fechamento forçado de posições lucrativas)
· Perdas socializadas (distribuição das perdas entre todos os usuários)
O tamanho do fundo de seguro em relação ao tamanho das posições abertas determina a frequência do ADL. O fundo de seguro da Binance totalizava cerca de US$ 2 bilhões em outubro de 2025. Em relação aos US$ 4 bilhões em contratos perpétuos abertos de BTC, ETH e BNB, isso fornecia 50% de cobertura. Mas durante o evento em cadeia de outubro, o total de contratos abertos em todos os pares excedeu US$ 20 bilhões. O fundo de seguro não pôde cobrir o déficit.
Após o evento em cadeia de outubro, a Binance anunciou que, enquanto o total de contratos abertos permanecer abaixo de US$ 4 bilhões, eles garantem que não haverá ADL nos contratos BTC, ETH e BNB USDⓈ-M. Isso cria uma estrutura de incentivos: a plataforma pode manter um fundo de seguro maior para evitar ADL, mas isso consome capital que poderia ser usado para gerar lucro.
Falhas on-chain: Limitações dos protocolos blockchain
O gráfico de barras compara o tempo de inatividade em diferentes eventos:
· Solana (fevereiro de 2024): 5 horas - gargalo de throughput de votação
· Polygon (março de 2024): 11 horas - incompatibilidade de versão dos validadores
· Optimism (junho de 2024): 2,5 horas - sobrecarga do sequenciador (airdrop)
· Solana (setembro de 2024): 4,5 horas - ataque de spam de transações
· Arbitrum (dezembro de 2024): 1,5 horas - falha do provedor RPC
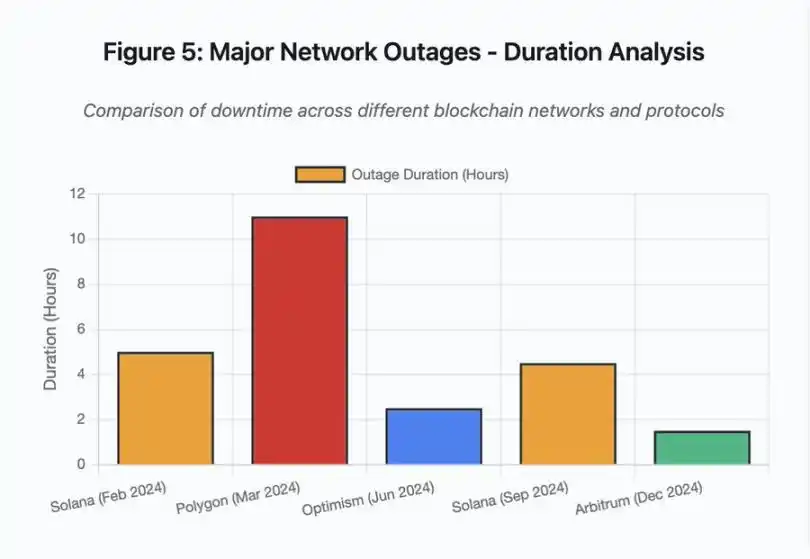
Figura 5: Principais interrupções de rede - análise de duração
Solana: Gargalo de consenso
Solana sofreu várias interrupções entre 2024 e 2025. A interrupção de fevereiro de 2024 durou cerca de 5 horas, e a de setembro de 2024 durou 4-5 horas. Ambas tiveram causas semelhantes: a rede não conseguiu processar o volume de transações durante ataques de spam ou atividade extrema.
Detalhe da Figura 5: As interrupções da Solana (5 horas em fevereiro, 4,5 horas em setembro) destacam problemas recorrentes de resiliência da rede sob pressão.
A arquitetura da Solana é otimizada para throughput. Em condições ideais, a rede processa 3.000-5.000 transações por segundo, com finalização subsegundo. Esse desempenho supera o Ethereum em várias ordens de magnitude. Mas durante eventos de estresse, essa otimização cria vulnerabilidades.
A interrupção de setembro de 2024 foi causada por uma enxurrada de transações spam que sobrecarregaram o mecanismo de votação dos validadores. Validadores Solana devem votar em blocos para alcançar consenso. Em operação normal, validadores priorizam transações de voto para garantir progresso do consenso. Mas o protocolo anteriormente tratava transações de voto como transações normais no mercado de taxas.
Quando o mempool ficou cheio de milhões de transações spam, os validadores tiveram dificuldade em propagar transações de voto. Sem votos suficientes, blocos não podiam ser finalizados. Sem blocos finalizados, a cadeia parou. Usuários com transações pendentes as viam presas no mempool. Novas transações não podiam ser enviadas.
StatusGator registrou várias interrupções da Solana entre 2024 e 2025, enquanto a Solana nunca reconheceu oficialmente. Isso criou assimetria de informação. Usuários não conseguiam distinguir problemas locais de conexão de problemas em toda a rede. Serviços de monitoramento de terceiros forneceram responsabilização, mas as plataformas deveriam manter páginas de status abrangentes.
Ethereum: Explosão das taxas de Gas
O Ethereum experimentou picos extremos de taxas de Gas durante o boom DeFi de 2021, com taxas de transação para transferências simples excedendo US$ 100. Interações complexas com contratos inteligentes custavam US$ 500-1.000. Essas taxas tornaram a rede inutilizável para transações de menor valor, ao mesmo tempo em que habilitaram um vetor de ataque diferente: extração de MEV.
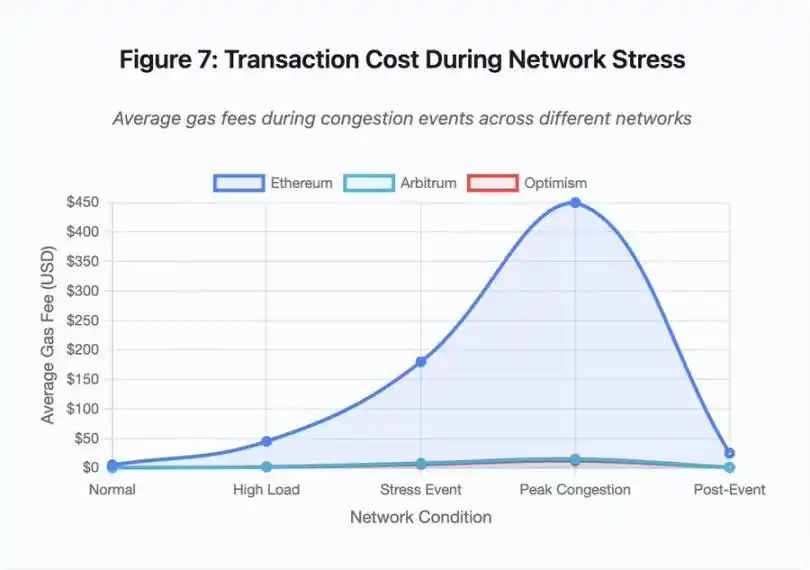
Figura 7: Custo de transação durante períodos de estresse na rede
Este gráfico de linha mostra dramaticamente a escalada das taxas de Gas durante eventos de estresse em diferentes redes:
· Ethereum: US$ 5 (normal) → US$ 450 (pico de congestionamento) - aumento de 90x
· Arbitrum: US$ 0,50 → US$ 15 - aumento de 30x
· Optimism: US$ 0,30 → US$ 12 - aumento de 40x
A visualização mostra que mesmo soluções Layer 2 experimentaram aumentos significativos nas taxas de Gas, embora partindo de níveis muito mais baixos.
Maximum Extractable Value (MEV) descreve o lucro que validadores podem extrair reordenando, incluindo ou excluindo transações. Em ambientes de alta taxa de Gas, o MEV torna-se especialmente lucrativo. Arbitradores competem para antecipar grandes negociações em DEXs, bots de liquidação competem para liquidar posições subcolateralizadas primeiro. Essa competição se manifesta em guerras de lances de Gas.
Usuários que desejam garantir inclusão de transações durante congestionamento devem oferecer taxas mais altas que bots de MEV. Isso cria situações em que a taxa de transação excede o valor da transação. Quer reivindicar seu airdrop de US$ 100? Pague US$ 150 em Gas. Precisa adicionar colateral para evitar liquidação? Compita com bots pagando US$ 500 de taxa de prioridade.
O limite de Gas do Ethereum restringe o total de computação por bloco. Durante congestionamento, usuários disputam o espaço escasso do bloco. O mercado de taxas funciona como projetado: quem paga mais tem prioridade. Mas esse design faz com que a rede se torne cada vez mais cara durante períodos de alta demanda — justamente quando os usuários mais precisam de acesso.
Soluções Layer 2 tentam resolver isso movendo a computação off-chain, enquanto herdam a segurança do Ethereum por liquidação periódica. Optimism, Arbitrum e outros rollups processam milhares de transações off-chain e então submetem provas comprimidas ao Ethereum. Essa arquitetura reduz com sucesso o custo por transação durante operações normais.
Layer 2: Gargalo do sequenciador
Mas soluções Layer 2 introduzem novos gargalos. O Optimism sofreu uma interrupção em junho de 2024 quando 250.000 endereços reivindicaram airdrops simultaneamente. O sequenciador — o componente que ordena transações antes de submetê-las ao Ethereum — ficou sobrecarregado, e usuários não puderam submeter transações por horas.
Essa interrupção mostra que mover a computação off-chain não elimina a necessidade de infraestrutura. O sequenciador deve processar transações recebidas, ordená-las, executá-las e gerar provas de fraude ou ZK para liquidação no Ethereum. Sob tráfego extremo, o sequenciador enfrenta os mesmos desafios de escalabilidade de blockchains independentes.
É necessário manter múltiplos provedores RPC disponíveis. Se o provedor principal falhar, usuários devem migrar automaticamente para alternativas. Durante a interrupção do Optimism, alguns provedores RPC continuaram funcionando, enquanto outros falharam. Usuários cujas wallets estavam conectadas ao provedor com falha não conseguiam interagir com a cadeia, mesmo que ela permanecesse online.
As interrupções da AWS repetidamente demonstraram o risco de infraestrutura centralizada no ecossistema cripto:
· 20 de outubro de 2025 (hoje): Interrupção na região Leste dos EUA afeta Coinbase, além de Venmo, Robinhood e Chime. AWS reconhece aumento de erros nos serviços DynamoDB e EC2.
· Abril de 2025: Interrupção regional afeta simultaneamente Binance, KuCoin e MEXC. Quando componentes hospedados na AWS falham, várias exchanges principais ficam indisponíveis.
· Dezembro de 2021: Interrupção na região Leste dos EUA paralisa Coinbase, Binance.US e a "descentralizada" dYdX por 8-9 horas, afetando também armazéns da Amazon e grandes serviços de streaming.
· Março de 2017: Interrupção do S3 impede usuários de acessar Coinbase e GDAX por cinco horas, junto com interrupções generalizadas na internet.
O padrão é claro: essas plataformas hospedam componentes críticos na infraestrutura da AWS. Quando a AWS sofre interrupções regionais, várias exchanges e serviços principais ficam indisponíveis simultaneamente. Usuários não conseguem acessar fundos, executar negociações ou modificar posições durante a interrupção — justamente quando a volatilidade do mercado pode exigir ação imediata.
Polygon: Incompatibilidade de versão de consenso
Polygon (anteriormente Matic) sofreu uma interrupção de 11 horas em março de 2024. A causa raiz envolveu incompatibilidade de versões dos validadores: alguns rodavam versões antigas do software, outros versões atualizadas. Essas versões calculavam transições de estado de maneira diferente.
Detalhe da Figura 5: A interrupção do Polygon (11 horas) foi a mais longa dos eventos analisados, destacando a gravidade das falhas de consenso.
Quando validadores chegam a conclusões diferentes sobre o estado correto, o consenso falha e a cadeia não pode produzir novos blocos, pois não há acordo sobre a validade dos blocos. Isso cria um impasse: validadores rodando software antigo rejeitam blocos produzidos por validadores com software novo, e vice-versa.
A solução exige coordenação para atualização dos validadores, mas durante a interrupção isso leva tempo. Cada operador de validador deve ser contatado, a versão correta do software deve ser implantada e o validador reiniciado. Em uma rede descentralizada com centenas de validadores independentes, essa coordenação pode levar horas ou dias.
Hard forks normalmente usam gatilhos de altura de bloco. Todos os validadores atualizam antes de uma altura específica, garantindo ativação simultânea, mas isso requer coordenação prévia. Atualizações incrementais, com validadores adotando novas versões gradualmente, correm o risco de criar exatamente a incompatibilidade de versões que causou a interrupção do Polygon.
Trade-offs de arquitetura
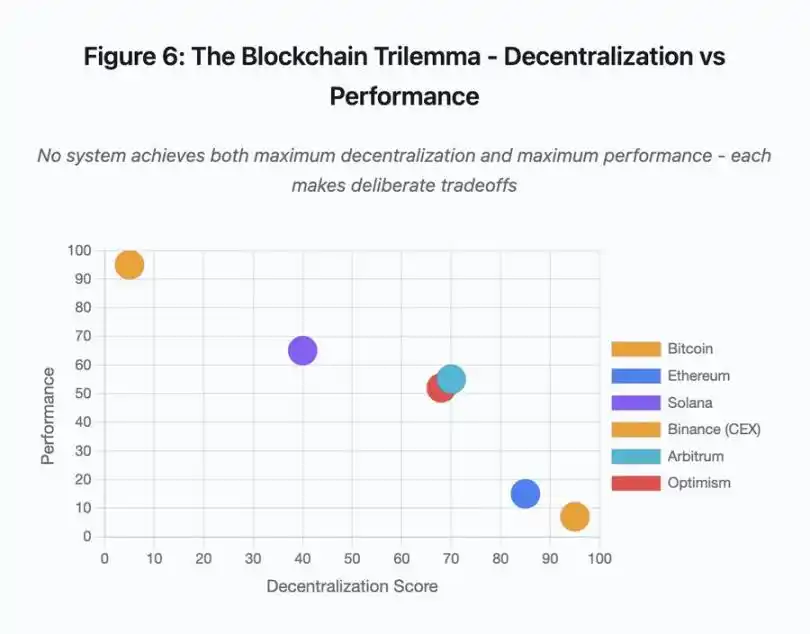
Figura 6: Trilema do blockchain - descentralização vs desempenho
Este gráfico de dispersão visualiza diferentes sistemas em dois eixos-chave:
· Bitcoin: alta descentralização, baixo desempenho
· Ethereum: alta descentralização, desempenho médio
· Solana: descentralização média, alto desempenho
· Binance (CEX): descentralização mínima, desempenho máximo
· Arbitrum/Optimism: descentralização média-alta, desempenho médio
Insight chave: nenhum sistema atinge simultaneamente máxima descentralização e máximo desempenho; cada design faz trade-offs cuidadosamente considerados para diferentes casos de uso.
Plataformas centralizadas de negociação alcançam baixa latência por meio de simplicidade arquitetural; motores de matching processam ordens em microssegundos, o estado reside em bancos de dados centralizados. Não há overhead de protocolo de consenso, mas essa simplicidade cria pontos únicos de falha, e falhas em cascata se propagam por sistemas fortemente acoplados sob pressão.
Protocolos descentralizados distribuem o estado entre validadores, eliminando pontos únicos de falha. Blockchains de alto throughput mantêm essa propriedade durante interrupções (fundos não são perdidos, apenas a atividade é temporariamente afetada). Mas alcançar consenso entre validadores distribuídos introduz overhead computacional; validadores devem concordar antes de finalizar transições de estado. Quando validadores rodam versões incompatíveis ou enfrentam tráfego excessivo, o consenso pode parar temporariamente.
Adicionar réplicas aumenta a tolerância a falhas, mas eleva o custo de coordenação. Em sistemas tolerantes a falhas bizantinas, cada validador adicional aumenta o overhead de comunicação. Arquiteturas de alto throughput minimizam esse overhead com comunicação otimizada entre validadores, alcançando desempenho superior, mas ficando vulneráveis a certos ataques. Arquiteturas focadas em segurança priorizam diversidade de validadores e robustez do consenso, limitando o throughput da camada base enquanto maximizam a resiliência.
Soluções Layer 2 tentam fornecer ambos atributos por design em camadas. Herdam a segurança do Ethereum via liquidação L1, enquanto oferecem alto throughput via computação off-chain. No entanto, introduzem novos gargalos no sequenciador e na camada RPC, mostrando que a complexidade arquitetural resolve alguns problemas, mas cria novos modos de falha.
Escalabilidade ainda é o problema fundamental
Esses eventos revelam um padrão consistente: sistemas são configurados para carga normal e falham catastroficamente sob pressão. Solana lida bem com tráfego regular, mas colapsa quando o volume de transações aumenta 10.000%. As taxas de Gas do Ethereum permanecem razoáveis até que a adoção do DeFi cause congestionamento. A infraestrutura do Optimism funciona bem até 250.000 endereços reivindicarem airdrops simultaneamente. As APIs da Binance funcionam normalmente, mas são limitadas durante liquidações em cadeia.
O evento de outubro de 2025 mostrou essa dinâmica no nível das exchanges. Durante operações normais, as limitações de taxa da API e as conexões de banco de dados da Binance são suficientes, mas durante liquidações em cadeia, quando cada trader tenta ajustar posições simultaneamente, esses limites tornam-se gargalos. O sistema de margem, projetado para proteger a exchange via liquidações forçadas, amplificou a crise ao criar vendedores forçados no pior momento possível.
Autoescalonamento oferece proteção insuficiente contra aumentos de carga em função degrau. Iniciar servidores adicionais leva minutos; durante esses minutos, sistemas de margem marcam o valor das posições com dados de preço corrompidos de livros de ordens rasos. Quando a nova capacidade entra em operação, a reação em cadeia já se espalhou.
Superdimensionar recursos para eventos raros de estresse consome capital durante operações normais. Operadores de exchanges otimizam para carga típica, aceitando falhas ocasionais como escolha economicamente racional. O custo do downtime é externalizado para os usuários, que enfrentam liquidações, negociações travadas ou inacessibilidade de fundos durante movimentos críticos do mercado.
Melhorias de infraestrutura
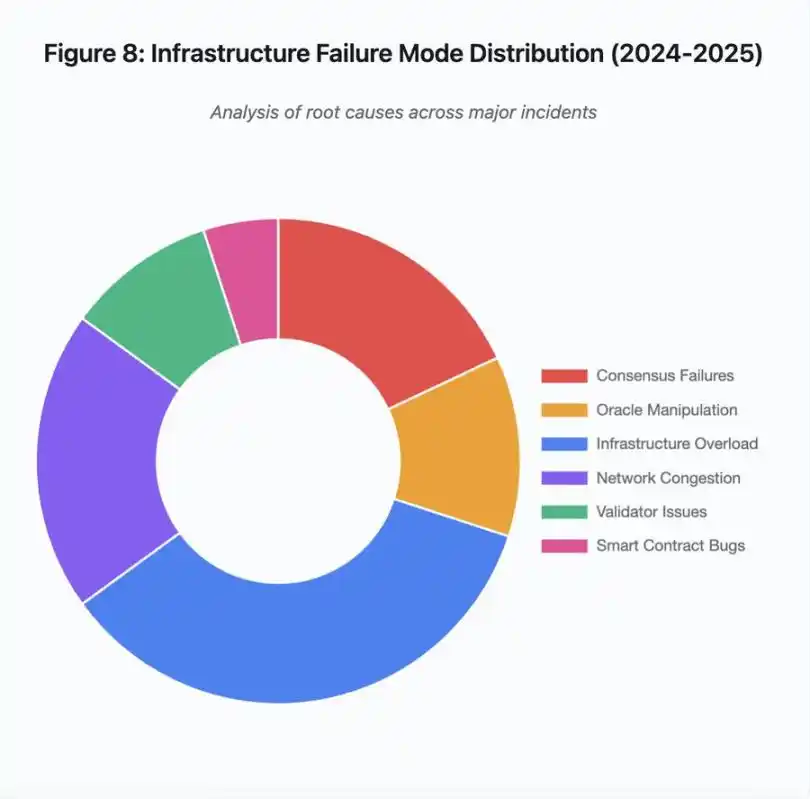
Figura 8: Distribuição dos modos de falha de infraestrutura (2024-2025)
O gráfico de pizza da causa raiz mostra:
· Sobrecarga de infraestrutura: 35% (mais comum)
· Congestionamento de rede: 20%
· Falha de consenso: 18%
· Manipulação de oráculo: 12%
· Problemas de validador: 10%
· Vulnerabilidades de contrato inteligente: 5%
Várias mudanças arquiteturais podem reduzir a frequência e a gravidade das falhas, embora cada uma envolva trade-offs:
Separação dos sistemas de precificação e liquidação
O problema de outubro originou-se em parte do acoplamento do cálculo de margem ao preço do mercado spot. Usar a taxa de troca para ativos embalados, em vez do preço spot, teria evitado a precificação incorreta do wBETH. Mais amplamente, sistemas críticos de gestão de risco não devem depender de dados de mercado potencialmente manipuláveis. Sistemas de oráculos independentes, com agregação multi-fonte e cálculo TWAP, fornecem fluxos de dados de preço mais robustos.
Superdimensionamento e infraestrutura redundante
A interrupção da AWS em abril de 2025, que afetou Binance, KuCoin e MEXC, demonstrou o risco da dependência de infraestrutura centralizada. Executar componentes críticos em múltiplos provedores de nuvem aumenta a complexidade e o custo operacional, mas elimina falhas correlacionadas. Redes Layer 2 podem manter múltiplos provedores RPC com failover automático. O custo extra parece desperdício durante operações normais, mas previne horas de downtime durante picos de demanda.
Testes de estresse aprimorados e planejamento de capacidade
O padrão de sistemas funcionando bem até falharem indica testes insuficientes sob pressão. Simular 100x a carga normal deveria ser prática padrão; identificar gargalos durante o desenvolvimento custa menos do que descobri-los durante interrupções reais. No entanto, testes de carga realistas ainda são desafiadores. O tráfego de produção exibe padrões que testes sintéticos não capturam totalmente, e o comportamento dos usuários durante colapsos reais difere do comportamento em testes.
Caminho a seguir
Superdimensionar recursos é a solução mais confiável, mas conflita com incentivos econômicos. Manter 10x a capacidade excedente para eventos raros custa dinheiro diariamente para evitar um problema anual. Até que falhas catastróficas imponham custos suficientes para justificar o superdimensionamento, os sistemas continuarão falhando sob pressão.
Pressão regulatória pode forçar mudanças. Se regulamentos exigirem 99,9% de uptime ou limitarem o downtime aceitável, plataformas precisarão superdimensionar. Mas regulações geralmente seguem desastres, não os previnem. O colapso da Mt. Gox em 2014 levou o Japão a criar regulamentação formal para exchanges cripto. O evento em cadeia de outubro de 2025 provavelmente provocará resposta regulatória semelhante. Resta saber se essas respostas especificarão resultados (downtime máximo aceitável, slippage máximo durante liquidações) ou métodos (provedores de oráculo específicos, limites de circuit breaker).
O desafio fundamental é que esses sistemas operam continuamente em mercados globais, mas dependem de infraestrutura projetada para horários comerciais tradicionais. Quando a pressão ocorre às 02:00, equipes correm para implementar correções enquanto usuários enfrentam perdas crescentes. Mercados tradicionais pausam negociações sob pressão; mercados cripto simplesmente colapsam. Se isso é uma característica ou um defeito depende da perspectiva e posição.
Sistemas blockchain alcançaram complexidade técnica significativa em pouco tempo. Manter consenso distribuído entre milhares de nós é uma verdadeira conquista de engenharia. Mas alcançar confiabilidade sob pressão exige ir além de arquiteturas prototípicas para infraestrutura de nível de produção. Essa transição requer capital e priorizar robustez sobre velocidade de desenvolvimento de funcionalidades.
O desafio é: durante bull markets, quando todos estão lucrando e downtime parece problema de outros, como priorizar robustez sobre crescimento? Quando o próximo ciclo testar os sistemas sob pressão, novas fraquezas aparecerão. Se a indústria aprenderá com outubro de 2025 ou repetirá padrões semelhantes ainda é uma questão em aberto. A história sugere que descobriremos a próxima vulnerabilidade crítica por meio de mais uma falha de bilhões de dólares sob pressão.
Aviso Legal: o conteúdo deste artigo reflete exclusivamente a opinião do autor e não representa a plataforma. Este artigo não deve servir como referência para a tomada de decisões de investimento.
Talvez também goste
Hyperliquid (HYPE) vai se recuperar? Esta configuração fractal emergente chave sugere que sim!

Altcoins vão se recuperar? Esta formação de padrão chave no BTC.D sugere que sim!

O ano mais crucial! O mercado está sendo profundamente manipulado, e é assim que as baleias realmente lucram
