Na szczycie wyszukiwań! Model dużej skali Meituan zyskał popularność dzięki „szybkości”

Deweloperzy z kraju i zagranicy: Przetestowaliśmy, nowy open-source model od Meituan jest superszybki!
Kiedy AI naprawdę stanie się tak powszechne jak woda i prąd, siła modelu przestaje być jedynym, co wszystkich interesuje.
Od początku roku, od Claude 3.7 Sonnet, Gemini 2.5 Flash po najnowsze GPT-5 i DeepSeek V3.1, czołowi producenci modeli nieustannie zastanawiają się: jak zapewnić, by AI, przy zachowaniu dokładności, rozwiązywało każdy problem przy minimalnym zużyciu mocy obliczeniowej i odpowiadało w najkrótszym możliwym czasie? Innymi słowy, jak nie marnować tokenów ani czasu.
Dla firm i deweloperów budujących aplikacje na bazie modeli, ta zmiana z „budowania najsilniejszego modelu” na „budowanie bardziej praktycznego i szybszego modelu” to dobra wiadomość. Co więcej, coraz więcej modeli open-source pojawia się w tym obszarze.
Kilka dni temu, na HuggingFace odkryliśmy nowy model — LongCat-Flash-Chat.

Ten model pochodzi z serii LongCat-Flash od Meituan, dostępny bezpośrednio na oficjalnej stronie.
Model ten naturalnie rozumie, że „nie wszystkie tokeny są równe”, dlatego dynamicznie przydziela budżet obliczeniowy ważniejszym tokenom. Dzięki temu, aktywując jedynie niewielką liczbę parametrów, osiąga wydajność porównywalną z czołowymi modelami open-source.

LongCat-Flash po otwarciu kodu trafił na listę trendów.
Jednocześnie prędkość tego modelu zrobiła na wszystkich ogromne wrażenie — na karcie graficznej H800 osiąga ponad 100 tokenów na sekundę. Testy deweloperów z kraju i zagranicy to potwierdziły — niektórzy uzyskali prędkość 95 tokens/s, inni w bardzo krótkim czasie otrzymali odpowiedzi porównywalne z Claude.
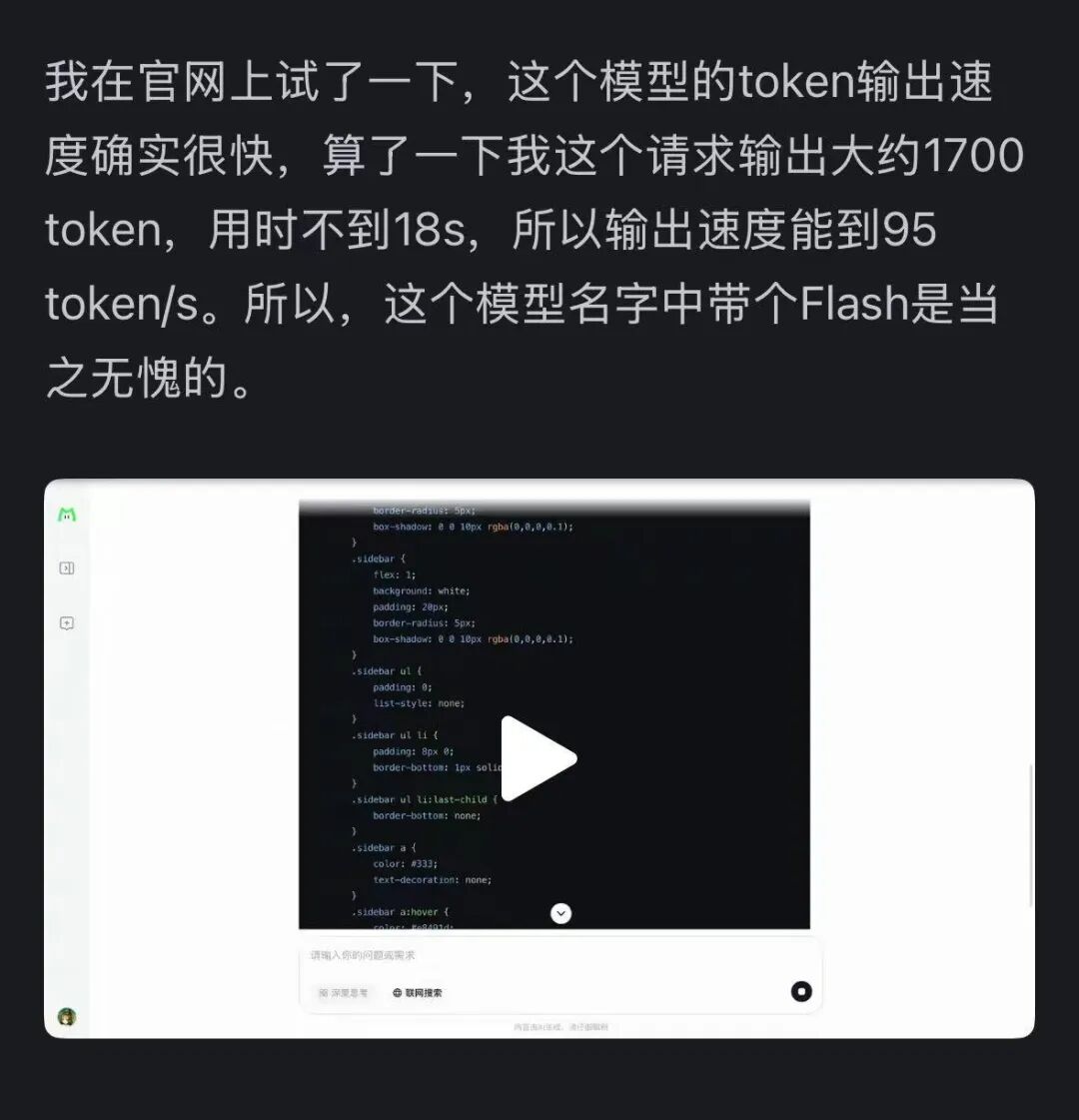
Źródło: użytkownik Zhihu @小小将.
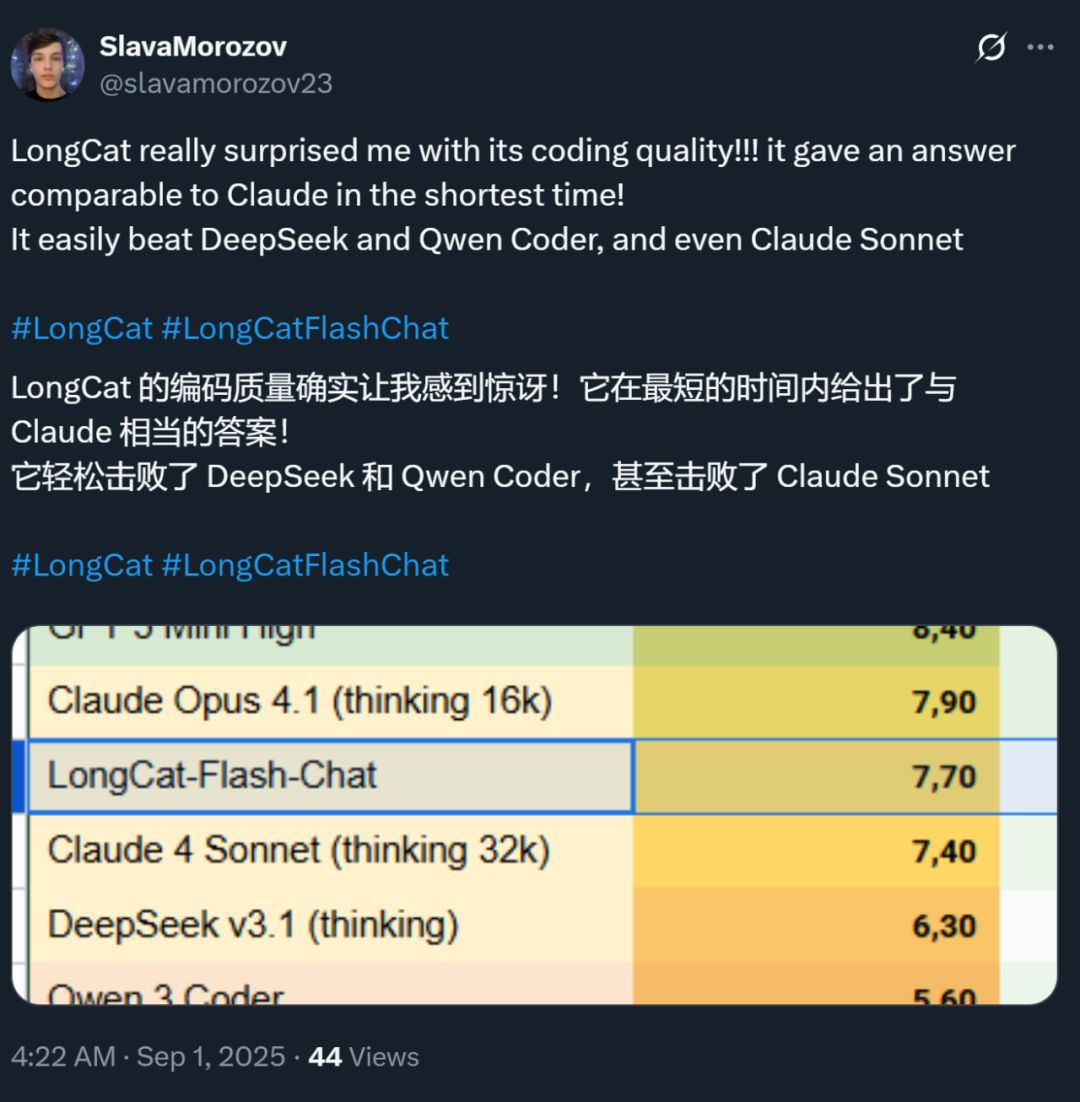
Źródło: użytkownik X @SlavaMorozov.
Wraz z otwarciem modelu Meituan udostępnił także raport techniczny LongCat-Flash, w którym znajdziemy wiele szczegółów technicznych.

Raport techniczny: LongCat-Flash Technical Report
W tym artykule przedstawimy szczegóły.
Jak duże modele oszczędzają moc obliczeniową?
Zobaczmy innowacje architektoniczne i metody treningu LongCat-Flash
LongCat-Flash to model mieszanych ekspertów o łącznej liczbie 560 miliardów parametrów, który może aktywować od 18.6 miliarda do 31.3 miliarda (średnio 27 miliardów) parametrów w zależności od kontekstu.
Do treningu tego modelu użyto ponad 20 bilionów tokenów, ale czas treningu wyniósł mniej niż 30 dni. W tym czasie system osiągnął 98,48% dostępności, praktycznie nie wymagając interwencji człowieka przy awariach — oznacza to, że cały proces treningu był niemal w pełni zautomatyzowany.
Jeszcze bardziej imponujące jest to, że model ten równie dobrze sprawdza się w praktycznym wdrożeniu.
Jak pokazano na poniższym wykresie, jako model nie-refleksyjny, LongCat-Flash osiąga wydajność porównywalną z SOTA nie-refleksyjnymi modelami, takimi jak DeepSeek-V3.1 i Kimi-K2, przy mniejszej liczbie parametrów i szybszym wnioskowaniu. Dzięki temu jest konkurencyjny i praktyczny w zastosowaniach ogólnych, programistycznych i narzędziowych.
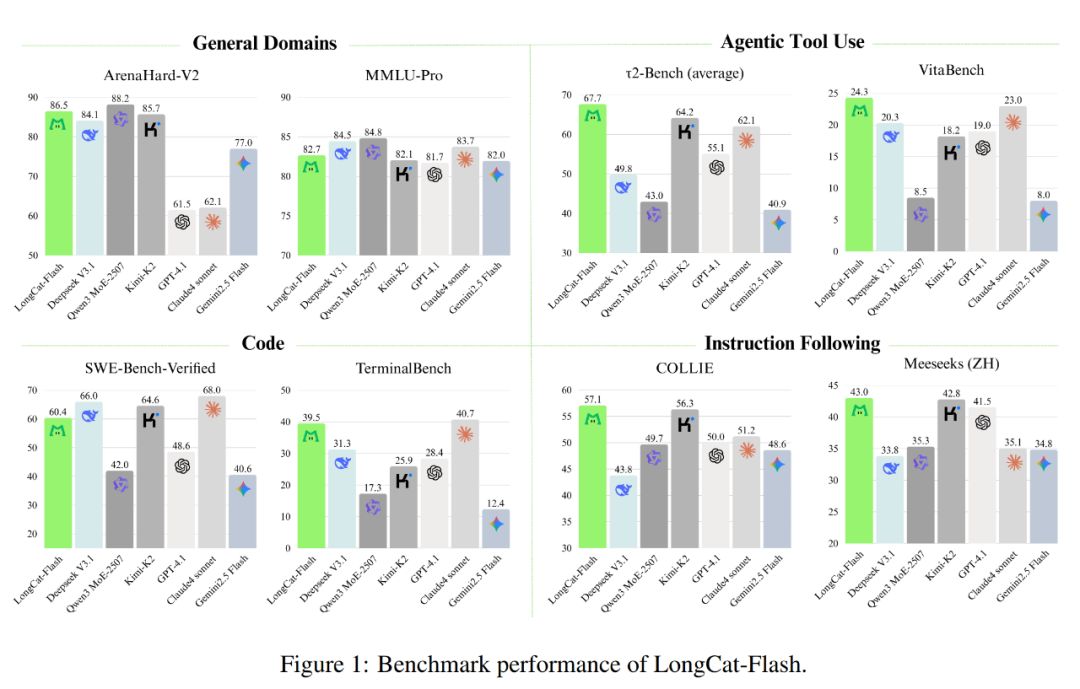
Ponadto jego koszt jest bardzo atrakcyjny — 0,7 USD za milion wyjściowych tokenów. W porównaniu z modelami o podobnej skali na rynku, to bardzo korzystna cena.
Pod względem technicznym LongCat-Flash skupia się na dwóch celach modeli językowych: wydajności obliczeniowej i zdolnościach agentowych, łącząc innowacje architektoniczne i wieloetapowe metody treningu, by stworzyć skalowalny i inteligentny system modeli.
W architekturze modelu LongCat-Flash zastosowano nowatorską architekturę MoE (rys. 2), której główne zalety to:
Eksperci zerowego obliczenia (Zero-computation Experts);
Skrótowe połączenie MoE (Shortcut-connected MoE, ScMoE).
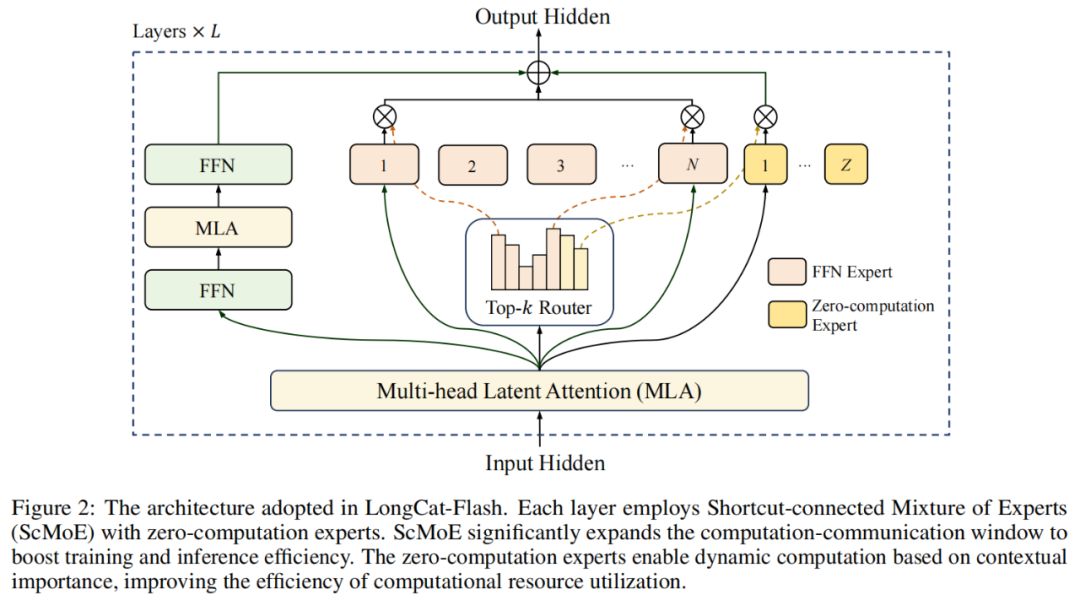
Eksperci zerowego obliczenia
Główna idea ekspertów zerowego obliczenia polega na tym, że nie wszystkie tokeny są „równe”.
Można to zrozumieć tak: w zdaniu niektóre słowa są bardzo łatwe do przewidzenia, np. „的”, „是”, i nie wymagają praktycznie żadnych obliczeń, podczas gdy inne, np. imiona, wymagają znacznie więcej mocy obliczeniowej, by je dokładnie przewidzieć.
W dotychczasowych badaniach zwykle stosowano podejście, w którym niezależnie od tego, czy token jest prosty czy złożony, aktywuje się stałą liczbę (K) ekspertów, co prowadzi do ogromnego marnotrawstwa mocy obliczeniowej. Dla prostych tokenów nie ma potrzeby angażowania tylu ekspertów, a dla złożonych może brakować wystarczających zasobów.
Inspirując się tym, LongCat-Flash wprowadził mechanizm dynamicznego przydzielania zasobów obliczeniowych: poprzez ekspertów zerowego obliczenia, dla każdego tokena dynamicznie aktywuje różną liczbę ekspertów FFN (Feed-Forward Network), by lepiej rozdzielać moc obliczeniową w zależności od ważności kontekstu.
W praktyce, w puli ekspertów LongCat-Flash, oprócz standardowych N ekspertów FFN, dodano Z ekspertów zerowego obliczenia. Eksperci ci po prostu zwracają wejście jako wyjście, nie generując dodatkowego obciążenia obliczeniowego.
Moduł MoE w LongCat-Flash można sformalizować następująco:
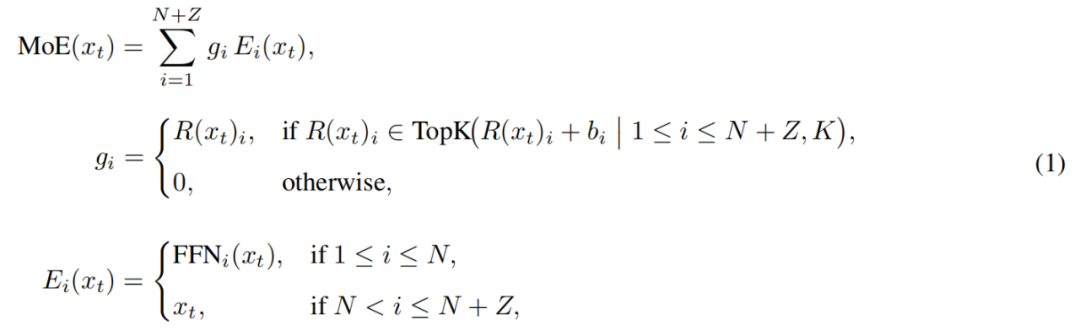
Gdzie x_t to t-ty token w sekwencji wejściowej, R to router softmax, b_i to bias i-tego eksperta, a K to liczba ekspertów wybranych dla każdego tokena. Router przydziela każdy token do K ekspertów, a liczba aktywowanych ekspertów FFN zmienia się w zależności od ważności tokena w kontekście. Dzięki temu adaptacyjnemu mechanizmowi model uczy się dynamicznie przydzielać więcej zasobów obliczeniowych ważniejszym tokenom, osiągając lepszą wydajność przy tej samej mocy obliczeniowej, jak pokazano na rys. 3a.
Model musi także nauczyć się, czy warto poświęcić więcej zasobów obliczeniowych na dany token w zależności od jego ważności. Jeśli nie kontroluje się częstotliwości wyboru ekspertów zerowego obliczenia, model może preferować ekspertów z obliczeniami, ignorując tych zerowych, co prowadzi do niskiej efektywności wykorzystania zasobów.
Aby rozwiązać ten problem, Meituan ulepszył mechanizm biasu ekspertów w strategii aux-loss-free: wprowadzono bias specyficzny dla eksperta, który dynamicznie dostosowuje wynik routera na podstawie ostatniego użycia eksperta, jednocześnie pozostając niezależnym od celu treningu modelu językowego.
Zasady aktualizacji wykorzystują regulator PID z teorii sterowania do bieżącej regulacji biasu ekspertów. Dzięki temu, przy przetwarzaniu każdego tokena, model aktywuje tylko 18.6–31.3 miliarda (średnio ok. 27 miliardów) parametrów, optymalizując wykorzystanie zasobów.
Skrótowe połączenie MoE
Kolejną zaletą LongCat-Flash jest mechanizm skrótowego połączenia MoE.
Zazwyczaj wydajność dużych modeli MoE jest ograniczona przez koszty komunikacji. W tradycyjnym podejściu eksperci równolegli wprowadzają sekwencyjny przepływ pracy: najpierw trzeba przekierować tokeny do odpowiednich ekspertów przez globalną komunikację, a dopiero potem rozpocząć obliczenia.
Ta sekwencja komunikacja-obliczenia powoduje dodatkowe opóźnienia, zwłaszcza w dużych systemach rozproszonych, gdzie opóźnienia komunikacyjne stają się wąskim gardłem wydajności.
Wcześniej badacze próbowali rozwiązać ten problem przez architekturę współdzielonych ekspertów, łącząc komunikację z obliczeniami pojedynczego eksperta, ale efektywność była ograniczona przez zbyt małe okno obliczeniowe.
Meituan, wprowadzając architekturę ScMoE, przezwyciężył to ograniczenie. ScMoE dodaje skrótowe połączenie między warstwami, co pozwala na równoległe wykonywanie obliczeń gęstego FFN z komunikacją rozdzielania/łączenia MoE, tworząc większe okno nakładania komunikacji i obliczeń niż w architekturze współdzielonych ekspertów.
Projekt ten został potwierdzony w wielu eksperymentach.
Po pierwsze, ScMoE nie obniża jakości modelu. Jak pokazano na rys. 4, krzywe strat podczas treningu dla architektury ScMoE i bazowej bez ScMoE są niemal identyczne, co dowodzi, że zmiana kolejności wykonywania nie szkodzi wydajności modelu. Potwierdzono to w różnych konfiguracjach.
Co ważniejsze, wyniki te pokazują, że stabilność i przewaga wydajnościowa ScMoE są ortogonalne do wyboru mechanizmu uwagi (czyli niezależnie od użytej uwagi, stabilność i korzyści są zachowane).
Po drugie, architektura ScMoE zapewnia znaczne usprawnienia systemowe podczas treningu i wnioskowania. Przejawia się to w:
Podczas treningu na dużą skalę: rozszerzone okno nakładania pozwala na pełną równoległość obliczeń poprzednich bloków z fazami rozdzielania i łączenia komunikacji w warstwie MoE, co osiągnięto przez podział operacji na drobne bloki wzdłuż wymiaru tokenów.
Podczas efektywnego wnioskowania: ScMoE obsługuje nakładanie pipeline w pojedynczej partii, co w porównaniu do czołowych modeli jak DeepSeek-V3, obniża teoretyczny czas generacji tokena (TPOT) o prawie 50%. Co ważniejsze, pozwala na równoległe wykonywanie różnych trybów komunikacji: komunikacja tensorowa w gęstym FFN (przez NVLink) może być w pełni nakładana z komunikacją ekspertów między węzłami (przez RDMA), maksymalizując wykorzystanie całej sieci.
Podsumowując, ScMoE zapewnia znaczny wzrost wydajności bez utraty jakości modelu.
Strategia skalowania modelu i wieloetapowy trening
Meituan zaproponował także wydajną strategię skalowania modelu, która znacząco poprawia wydajność przy zwiększaniu skali.
Po pierwsze, transfer hiperparametrów — podczas treningu bardzo dużych modeli bezpośrednie testowanie różnych konfiguracji hiperparametrów jest kosztowne i niestabilne. Meituan najpierw eksperymentuje na mniejszych modelach, by znaleźć najlepsze kombinacje, a następnie przenosi te parametry do dużych modeli, oszczędzając koszty i zapewniając efekty. Zasady transferu pokazano w tabeli 1:
Kolejny krok to inicjalizacja wzrostu modelu (Model Growth) — Meituan zaczyna od modelu o połowie docelowej wielkości, wytrenowanego na setkach miliardów tokenów, zachowuje checkpoint, a następnie rozbudowuje model do pełnej skali i kontynuuje trening.
Dzięki temu model wykazuje typową krzywą strat: najpierw krótkotrwały wzrost, potem szybka konwergencja i ostatecznie znacznie lepsze wyniki niż losowa inicjalizacja. Rys. 5b pokazuje reprezentatywny wynik eksperymentu z 6B aktywowanych parametrów, ilustrując zalety tej metody.
Trzeci element to wielopoziomowy zestaw stabilizujący — Meituan poprawił stabilność treningu LongCat-Flash na trzech poziomach: routera, aktywacji i optymalizatora.
Czwarty to deterministyczne obliczenia, które zapewniają pełną powtarzalność wyników eksperymentów i wykrywanie cichego uszkodzenia danych (Silent Data Corruption, SDC) podczas treningu.
Dzięki tym środkom trening LongCat-Flash pozostaje bardzo stabilny i nie występują nieodwracalne skoki strat.
Na bazie stabilnego treningu Meituan starannie zaprojektował pipeline treningowy, by LongCat-Flash posiadał zaawansowane zachowania agentowe. Proces obejmuje pre-trening na dużą skalę, trening środkowy skupiony na wnioskowaniu i kodowaniu oraz post-trening skoncentrowany na dialogu i użyciu narzędzi.
W fazie początkowej zbudowano bazowy model lepiej przystosowany do post-treningu agentowego; Meituan opracował dwufazową strategię łączenia danych pre-treningowych, by skoncentrować się na danych z obszarów wymagających intensywnego wnioskowania.
W fazie środkowej Meituan wzmocnił zdolności wnioskowania i kodowania modelu oraz wydłużył kontekst do 128k, by sprostać wymaganiom post-treningu agentowego.
Na końcu przeprowadzono wieloetapowy post-trening. Ze względu na niedobór wysokiej jakości, trudnych danych treningowych w dziedzinie agentów, Meituan opracował wieloagentowy framework syntetyczny: definiuje on trudność zadań w trzech wymiarach — przetwarzania informacji, złożoności zestawu narzędzi i interakcji z użytkownikiem, a specjalny kontroler generuje złożone zadania wymagające iteracyjnego wnioskowania i interakcji ze środowiskiem.
Dzięki temu model świetnie radzi sobie z zadaniami wymagającymi użycia narzędzi i interakcji ze środowiskiem.
Działa szybko i tanio
Jak LongCat-Flash to osiąga?
Jak wspomniano wcześniej, LongCat-Flash może wnioskować na karcie H800 z prędkością ponad 100 tokenów na sekundę, a koszt to tylko 0,7 USD za milion wyjściowych tokenów — działa więc szybko i tanio.
Jak to możliwe? Po pierwsze, mają architekturę równoległego wnioskowania współprojektowaną z architekturą modelu; po drugie, zastosowali optymalizacje takie jak kwantyzacja i własne jądra.
Dedykowane optymalizacje: by model „sam biegł płynnie”
Aby zbudować wydajny system wnioskowania, trzeba rozwiązać dwa kluczowe problemy: koordynację obliczeń i komunikacji oraz odczyt/zapis i przechowywanie cache KV.
Wobec pierwszego wyzwania, dotychczasowe metody wykorzystywały trzy poziomy równoległości: nakładanie na poziomie operatora, eksperta i warstwy. Architektura ScMoE w LongCat-Flash wprowadza czwarty wymiar — nakładanie na poziomie modułu. W tym celu zespół opracował strategię harmonogramowania SBO (Single Batch Overlap) dla optymalizacji opóźnień i przepustowości.
SBO to czterofazowy pipeline, który w pełni wykorzystuje potencjał LongCat-Flash dzięki nakładaniu na poziomie modułu, jak pokazano na rys. 9. W odróżnieniu od TBO, SBO ukrywa koszty komunikacji w ramach pojedynczej partii. W pierwszej fazie wykonuje się obliczenia MLA, dostarczając dane do kolejnych faz; w drugiej fazie Dense FFN i Attn 0 (projekcja QKV) nakładają się z komunikacją all-to-all dispatch; w trzeciej fazie niezależnie wykonuje się MoE GEMM, korzystając z szerokiej strategii wdrożenia EP; w czwartej fazie Attn 1 (główna uwaga i projekcja wyjściowa) oraz Dense FFN nakładają się z all-to-all combine. To rozwiązanie skutecznie ogranicza koszty komunikacji i zapewnia wysoką wydajność wnioskowania LongCat-Flash.
Drugie wyzwanie — odczyt/zapis i przechowywanie cache KV — LongCat-Flash rozwiązuje dzięki innowacjom w mechanizmie uwagi i architekturze MTP, redukując efektywne koszty I/O.
Najpierw przyspieszenie dekodowania spekulacyjnego. LongCat-Flash wykorzystuje MTP jako model szkicowy, optymalizując trzy kluczowe czynniki: oczekiwaną długość akceptacji, stosunek kosztów modelu szkicowego do docelowego oraz stosunek kosztów walidacji do dekodowania. Integrując pojedynczą głowicę MTP i wprowadzając ją w późnej fazie pre-treningu, osiągnięto ok. 90% akceptacji. By zrównoważyć jakość szkicu i prędkość, zastosowano lekką architekturę MTP i metodę C2T do filtrowania tokenów mało prawdopodobnych do akceptacji.
Następnie optymalizacja cache KV przez 64-głowicowy mechanizm uwagi MLA. MLA, zachowując równowagę między wydajnością a efektywnością, znacząco redukuje obciążenie obliczeniowe i zapewnia doskonałą kompresję cache KV, zmniejszając presję na pamięć i przepustowość. To kluczowe dla koordynacji pipeline LongCat-Flash, ponieważ model zawsze ma obliczenia uwagi, których nie można nakładać z komunikacją.
Optymalizacje systemowe: by sprzęt „współpracował zespołowo”
Aby zminimalizować koszty harmonogramowania, zespół LongCat-Flash rozwiązał problem launch-bound w systemach wnioskowania LLM, wynikający z kosztów uruchamiania jąder. Zwłaszcza po wprowadzeniu dekodowania spekulacyjnego, niezależne harmonogramowanie jąder walidacyjnych i forward szkicu generuje znaczne koszty. Dzięki strategii fuzji TVD połączono forward docelowy, walidację i forward szkicu w jeden wykres CUDA. By dalej zwiększyć wykorzystanie GPU, wdrożono harmonogramowanie nakładające się i wprowadzono wieloetapowy harmonogram nakładania, uruchamiający wiele kroków forward w jednej iteracji, skutecznie ukrywając koszty harmonogramowania CPU i synchronizacji.
Własne jądra zoptymalizowano pod kątem specyficznych wyzwań wydajnościowych autoregresywnych LLM. Faza pre-fill jest intensywna obliczeniowo, a faza dekodowania — ze względu na wzorce przepływu — często ograniczona przez pamięć z powodu małych, nieregularnych rozmiarów partii. W przypadku MoE GEMM zastosowano technikę SwapAB, traktując wagi jako lewą macierz, aktywacje jako prawą, maksymalizując wykorzystanie rdzeni tensorowych dzięki elastyczności 8-elementowych bloków w wymiarze n. Jądra komunikacyjne wykorzystują sprzętowe przyspieszenie NVLink Sharp do broadcastu i in-switch reduction, minimalizując ruch danych i wykorzystanie SM, przewyższając NCCL i MSCCL++ w zakresie rozmiarów wiadomości od 4KB do 96MB przy użyciu tylko 4 bloków wątków.
W zakresie kwantyzacji LongCat-Flash stosuje tę samą precyzyjną kwantyzację blokową co DeepSeek-V3. Dla najlepszego kompromisu między wydajnością a dokładnością wdrożono mieszane precyzje na poziomie warstw na podstawie dwóch schematów: pierwszy wykrywa, że wejścia niektórych warstw liniowych (zwłaszcza Downproj) osiągają ekstremalne amplitudy do 10^6; drugi oblicza błąd kwantyzacji FP8 na poziomie bloku dla każdej warstwy, wykrywając znaczne błędy w niektórych warstwach eksperckich. Przecięcie obu schematów zapewnia znaczną poprawę dokładności.
Dane z praktyki: jak szybko i jak tanio?
Testy pokazują, że LongCat-Flash osiąga znakomite wyniki w różnych konfiguracjach. W porównaniu do DeepSeek-V3, przy podobnej długości kontekstu, LongCat-Flash zapewnia wyższą przepustowość i szybszą generację.
W aplikacjach Agent, biorąc pod uwagę różne wymagania dotyczące treści wnioskowania (widoczne dla użytkownika, muszą odpowiadać prędkości czytania człowieka ok. 20 tokens/s) i poleceń akcji (niewidoczne dla użytkownika, ale bezpośrednio wpływające na czas uruchomienia narzędzi, wymagające maksymalnej prędkości), prędkość generacji LongCat-Flash bliska 100 tokens/s pozwala utrzymać opóźnienie pojedynczego wywołania narzędzia poniżej 1 sekundy, znacznie poprawiając interaktywność aplikacji Agent. Przy założeniu kosztu 2 USD za godzinę GPU H800, oznacza to 0,7 USD za milion wyjściowych tokenów.
Analiza teoretyczna pokazuje, że opóźnienie LongCat-Flash zależy głównie od trzech komponentów: MLA, all-to-all dispatch/combine i MoE. Przy EP=128, batch na kartę=96, akceptacja MTP ≈80%, teoretyczny limit TPOT LongCat-Flash to 16ms, znacznie lepiej niż 30ms dla DeepSeek-V3 i 26,2ms dla Qwen3-235B-A22B. Przy założeniu 2 USD za godzinę GPU H800, koszt wyjścia LongCat-Flash to 0,09 USD za milion tokenów, znacznie mniej niż 0,17 USD dla DeepSeek-V3. Jednak są to wartości teoretyczne.
Na stronie darmowego testowania LongCat-Flash również przeprowadziliśmy test.
Najpierw poprosiliśmy model o napisanie artykułu o jesieni, ok. 1000 słów.
Zaraz po zadaniu pytania i rozpoczęciu nagrywania ekranu, LongCat-Flash natychmiast wygenerował odpowiedź — nie zdążyliśmy nawet wyłączyć nagrywania na czas.
Przy bliższej obserwacji widać, że pierwszy token LongCat-Flash pojawia się wyjątkowo szybko. W innych modelach często trzeba czekać na „kręcące się kółko”, co wystawia cierpliwość użytkownika na próbę — jak wtedy, gdy czekasz na wiadomość na WeChat, a telefon pokazuje „pobieranie”. LongCat-Flash zmienia to doświadczenie — praktycznie nie czuć opóźnienia pierwszego tokena.
Kolejne tokeny generowane są równie szybko, znacznie szybciej niż tempo czytania ludzkiego oka.
Następnie włączyliśmy „wyszukiwanie online”, by sprawdzić, czy LongCat-Flash radzi sobie równie szybko. Poprosiliśmy o polecenie dobrych restauracji w pobliżu Wangjing.
Test pokazał wyraźnie, że LongCat-Flash nie „zastanawia się długo”, tylko niemal natychmiast udziela odpowiedzi. Wyszukiwanie online również jest „szybkie”. Co więcej, podczas szybkiego generowania odpowiedzi model podaje źródła, zapewniając wiarygodność i możliwość weryfikacji informacji.
Osoby mogące pobrać model mogą przetestować LongCat-Flash lokalnie i sprawdzić, czy prędkość jest równie imponująca.
Gdy duże modele wchodzą w erę praktyczności
W ostatnich latach, gdy pojawiał się nowy duży model, wszyscy pytali: jakie ma wyniki benchmarków? Ile rankingów pobił? Czy jest SOTA? Dziś sytuacja się zmieniła. Przy podobnych możliwościach, ważniejsze jest: czy model jest tani w użyciu? Jaką ma prędkość? Wśród firm i deweloperów korzystających z open-source, to szczególnie widoczne. Wielu użytkowników wybiera open-source, by ograniczyć zależność i koszty związane z zamkniętymi API, więc są bardziej wrażliwi na wymagania obliczeniowe, prędkość wnioskowania i efekty kwantyzacji/kompresji.
LongCat-Flash od Meituan to przykład podążania za tym trendem. Skupili się na tym, jak sprawić, by duży model był naprawdę użyteczny i szybki — to klucz do popularyzacji technologii.
To praktyczne podejście jest zgodne z naszym dotychczasowym postrzeganiem Meituan. W przeszłości większość ich inwestycji technologicznych rozwiązywała realne problemy biznesowe, np. nagrodzona na ICRA 2022 praca EDPLVO dotyczyła problemów dronów podczas dostaw (np. utrata sygnału przez zbyt gęstą zabudowę); ostatnio współtworzyli globalny standard ISO dla unikania przeszkód przez drony, oparty na doświadczeniach z omijania linek od latawców czy lin do mycia okien. Tym razem open-source’owy LongCat-Flash to model stojący za ich narzędziem AI do programowania „NoCode”, które służy zarówno wewnętrznie, jak i jest otwarte dla wszystkich — by każdy mógł korzystać z vibe coding, obniżając koszty i zwiększając efektywność.
Ta zmiana z wyścigu wydajności na praktyczność odzwierciedla naturalny rozwój branży AI. Gdy możliwości modeli się zbliżają, efektywność inżynieryjna i koszty wdrożenia stają się kluczowymi czynnikami różnicującymi. Open-source LongCat-Flash to tylko jeden z przykładów tego trendu, ale faktycznie daje społeczności technologiczną ścieżkę: jak, przy zachowaniu jakości modelu, obniżyć próg użycia dzięki innowacjom architektonicznym i optymalizacjom systemowym. Dla deweloperów i firm z ograniczonym budżetem, którzy chcą korzystać z zaawansowanych możliwości AI, to bez wątpienia wartościowe rozwiązanie.
Zastrzeżenie: Treść tego artykułu odzwierciedla wyłącznie opinię autora i nie reprezentuje platformy w żadnym charakterze. Niniejszy artykuł nie ma służyć jako punkt odniesienia przy podejmowaniu decyzji inwestycyjnych.
Może Ci się również spodobać
Strategie BTC w erze wysokowydajnych publicznych łańcuchów: rewolucja Solana i kapitału on-chain
W erze wydajnych blockchainów konkurencja nie sprowadza się już wyłącznie do wyścigu na TPS, lecz do tego, kto zbuduje bardziej dynamiczny i efektywny ekosystem gospodarczy on-chain.

WLFI strategicznie inkubuje BlockRock, tworząc nowy silnik instrumentów pochodnych finansowych RWA
Ta współpraca nie tylko oznacza głęboką ekspansję WLFI w sektorze RWA, ale także ustanawia BlockRock jako kluczową platformę RWA w jego ekosystemie.

Ekspansja zagraniczna przedsiębiorstw: wybór struktury i strategie optymalizacji podatkowej
Jak ważna jest odpowiednia struktura przedsiębiorstwa?

Ewolucja inwestycji w altcoiny z perspektywy $HYPE
W erze manipulowalnych wskaźników, jak przebić się przez narracyjną mgłę tokenomiki?